Self-Improving Loops: How AI Agents Learn From Experience
Self-improving loops let AI agents evaluate their own outputs, store lessons, and get better with each task cycle.

Most AI agents are weirdly forgetful. They finish a task, wipe the slate clean, and show up tomorrow ready to repeat the same mistake. No memory, no growth.
The self-improving loop breaks that cycle. The agent looks at its own results, learns what worked, and gets a little better each time.
This guide explains the self-improving loop in clear, simple language. You will learn how it works, why it beats traditional agent workflows, and where it adds real value. A runnable code example with dummy data is also included.
Understanding Traditional Agentic Workflows
Before we move to self-improving agents, we must understand the systems they upgrade. Traditional agentic workflows power most AI assistants you use today. They are powerful, popular, and good enough for many jobs. Still, they share one big weakness that limits long-term performance.
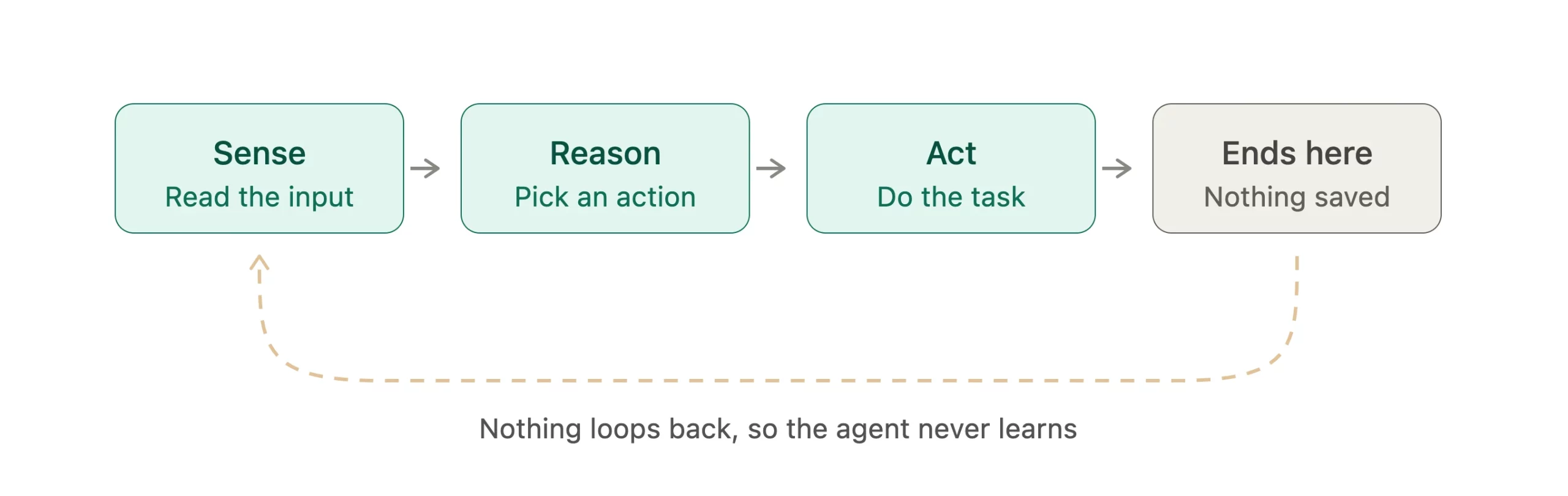
The workflow is linear: sense → reason → act, and then the process ends or moves to a new task without learning from the result.
Typical Agent Architecture
Most traditional agents share a simple, repeatable structure. Understanding these parts makes the later comparison much easier to follow. Below are the common building blocks of a standard agent.
- The prompt: Fixed instructions that tell the agent what to do and how to behave.
- The reasoning step: The model plans actions, often using a pattern like reason-then-act.
- The tools: Optional helpers such as web search, code runners, or databases.
- The output: The final response delivered back to the user once the task finishes.
Strengths of Traditional Agents
Traditional agents remain popular because they offer clear and reliable benefits. Here are the strengths that keep them relevant.
- Predictable behaviour: The same input usually produces a similar and stable output.
- Fast to build: A capable agent can ship in hours with modern frameworks.
- Easy to audit: Fixed prompts make the agent’s logic simple to review and debug.
- Low complexity: Fewer moving parts mean fewer things can break in production.
Key Limitations of Traditional Agents
Despite their simplicity, traditional agents have important downsides:
- No long-term learning: They do not retain knowledge beyond the immediate task. Each task starts fresh, so they repeat the same mistakes repeatedly.
- Static prompt and model: The agent’s instructions and model weights never change on the fly.
- No feedback loop: They lack a built-in evaluation step. Once an answer is given, the loop stops.
- Repeated errors: Without review, a mistake in reasoning or a wrong fact can persist indefinitely.
What is the Self-Improving Loop in AI Agents?
The self-improving loop is the upgrade that fixes the weaknesses above. It turns a one-shot worker into a system that learns from experience.
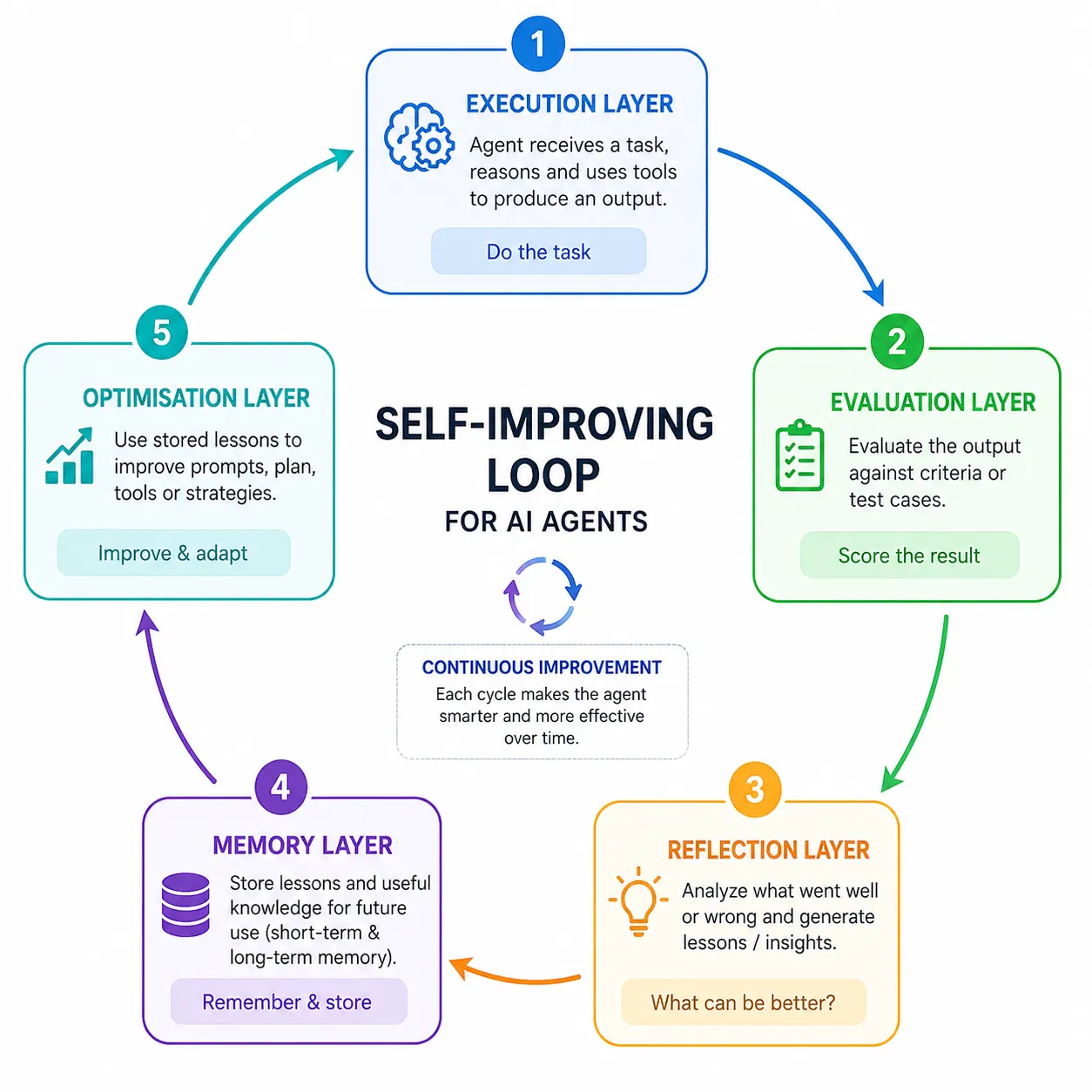
A self-improving agent does its task, checks its own result, and learns from what happened. It writes down useful lessons, stores them in memory, and applies them next time. With each cycle, the agent gets a little sharper. This continuous loop is the heart of self-improvement.
Why Self-Improvement Matters for Agent Performance
Self-improvement matters because it removes the need for constant human observation. The agent learns from real feedback instead of waiting for an engineer to fix it.
- Fewer repeated errors: Some teams report sharp drops in repeated mistakes once memory is added.
- Higher task completion: Studies suggest memory-equipped agents complete far more multi-step tasks successfully.
- Less manual upkeep: The agent adapts on its own, so engineers spend less time rewriting prompts.
- Compounding gains: Small improvements stack over time, much like interest in a savings account.
Core Components of a Self-Improving Agent
A self-improving agent is built from five working layers. Each layer has one clear job, and together they form the loop.
-
Execution Layer: The worker that does the task. It reads the request, reasons through a plan, and produces an output. This layer behaves much like a traditional agent on its own, but the other layers watch and guide it.
-
Evaluation Layer: Acts as a strict judge of the output. It scores the result against clear quality checks or test cases.
-
Reflection Layer: Asks a simple question: what went wrong and why? It turns a low score into plain-language lessons the agent can reuse, acting like a coach pointing out a specific weakness.
-
Memory Layer: Stores the lessons so they survive beyond a single task. Short-term memory holds the current conversation, while long-term memory holds lasting knowledge.
-
Optimisation Layer: Applies stored lessons to improve future behaviour. It may refine the prompt, reorder steps, or pick better tools. Over many cycles, this layer reshapes how the agent works.
Self-Improving Loop vs Traditional Agent Workflow
Placing both designs side by side makes the real difference clear. The contrast is sharpest when you watch how each one handles a mistake.
Architectural Comparison
The two architectures differ mainly in what happens after the output is produced. A traditional agent stops at the output, while a self-improving agent keeps going.
- Traditional agent: Prompt to reasoning to tools to output, then it stops.
- Self-improving agent: Prompt to reasoning to output, then evaluate, reflect, remember, and optimize.
- Memory: Traditional agents forget; self-improving agents store lessons across tasks.
- Feedback: Traditional agents have none; self-improving agents grade and correct themselves.
Workflow Comparison: Step-by-Step
Traditional Agent Workflow:
- Read the prompt and the user request.
- Reason through a plan and call any tools.
- Produce the final output.
- Stop, with no review and no memory saved.
Self-Improving Loop Workflow:
- Read the prompt and produce a first attempt.
- Evaluate the attempt against quality checks.
- Reflect on failures and write clear lessons.
- Save those lessons into long-term memory.
- Retry with the lessons applied, then reuse them on future tasks.
Feature-by-Feature Comparison
The table below summarizes the practical differences across the features that matter most for real projects.
| Feature | Traditional Agent | Self-Improving Agent |
|---|---|---|
| Learning across tasks | No | Yes |
| Feedback loop | None | Built-in evaluate and reflect steps |
| Memory | None beyond current context | Short-term and long-term |
| Error correction | Manual, by an engineer | Automatic, by the agent itself |
| Prompt adaptation | Static | Dynamic, updated from lessons |
| Setup complexity | Low | Higher, but manageable |
| Long-term performance | Flat | Improves with each cycle |
The self-improving loop does add complexity, but the payoff is an agent that gets measurably better over time without requiring constant human intervention. For tasks that repeat, involve multi-step reasoning, or demand high accuracy, that compounding improvement makes the additional setup worthwhile.