Prompt Engineering for Agentic AI: Principles and Patterns
Agentic AI requires a different prompting discipline than chatbots. Learn the four components, reasoning architectures, and patterns that make agents reliable.
In this article, you will learn how prompt engineering changes fundamentally when applied to agentic AI systems, and what principles and patterns enable reliable agent behavior at scale.
Topics we will cover include:
- Why prompting agents differs from prompting chatbots, and what context engineering means in practice.
- The four components every agent prompt needs, including system prompts, tools, examples, and context state management.
- The reasoning architectures that make agents more reliable, from chain of thought to ReAct and Reflexion.
Introduction
You have probably spent time learning how to prompt AI well. Better phrasing, clearer instructions, more context upfront. That knowledge is genuinely useful, and it will take you only so far once you move into agentic AI.
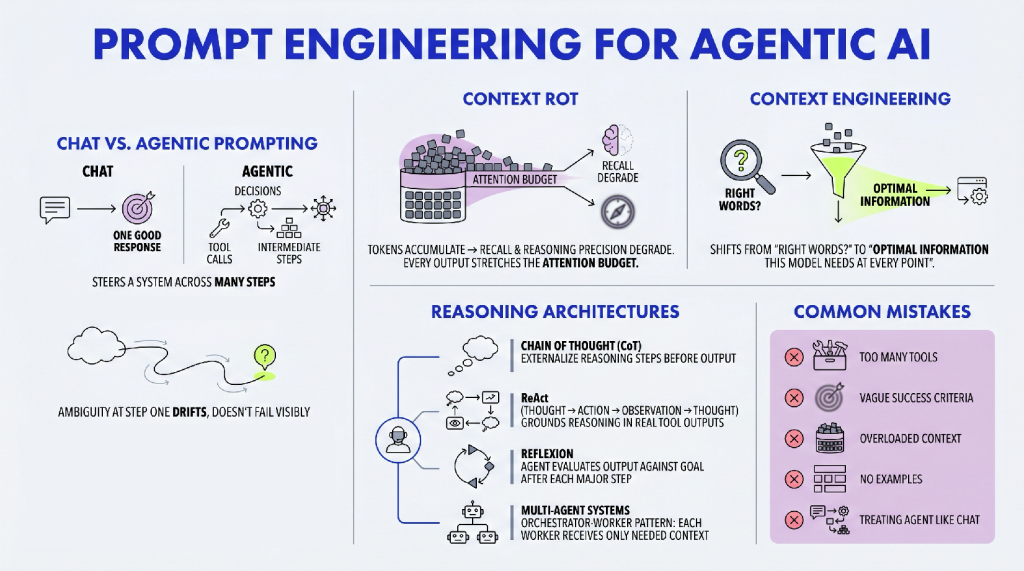
The prompting skills that work in a chat window break down the moment the AI starts taking actions across multiple steps. A well-crafted question produces one good response. A well-designed agent prompt steers a system that reads files, calls APIs, makes decisions, delegates to sub-agents, recovers from errors, and delivers a finished output, all without you shepherding each step. Those are two different disciplines. One is asking. The other is designing how a system thinks.
This article is about the second thing. It is written for builders and practitioners who are moving past chat and into agents, people who want to know how prompting actually works inside autonomous systems, what the reliable patterns look like, and where most people go wrong.
Why Prompting an Agent is Different From Prompting a Chatbot
When you prompt a chatbot, your only job is to produce a good next response. You write something, the model replies, you adjust and go again. The feedback loop is short and visible. If the output is wrong, you can see it immediately and re-prompt.
Agents do not work that way. An agent receives a goal, builds a plan, executes it across many steps, uses tools, generates intermediate outputs that feed into later steps, and eventually delivers a final result. The problem is that an ambiguous instruction at step one does not visibly fail at step one; it drifts. By step seven, the agent is technically doing what it inferred from your prompt, which may be something you never intended. And by that point, you have already consumed significant compute, time, and tool calls getting there.
This is the core challenge of agentic prompting: the effects of your prompt are distributed across time and steps, not concentrated in a single response.
There is also a structural issue that compounds this. Research on context degradation shows that as the number of tokens in an agent’s context window grows, the model’s ability to accurately recall and reason over that information decreases, a phenomenon researchers call context rot. Every tool call result, every intermediate output, every completed step adds tokens. By the middle of a long task, an agent operating on a poorly designed context may lose track of constraints that were clearly stated at the beginning.
This is exactly why Anthropic’s engineering team introduced the concept of context engineering as the natural evolution of prompt engineering. Their framing: prompt engineering asks “what are the right words?” Context engineering asks “what is the optimal set of information this model should have at every point during execution?” That is a bigger, more architectural question, and it is the right question for building agents that behave reliably.
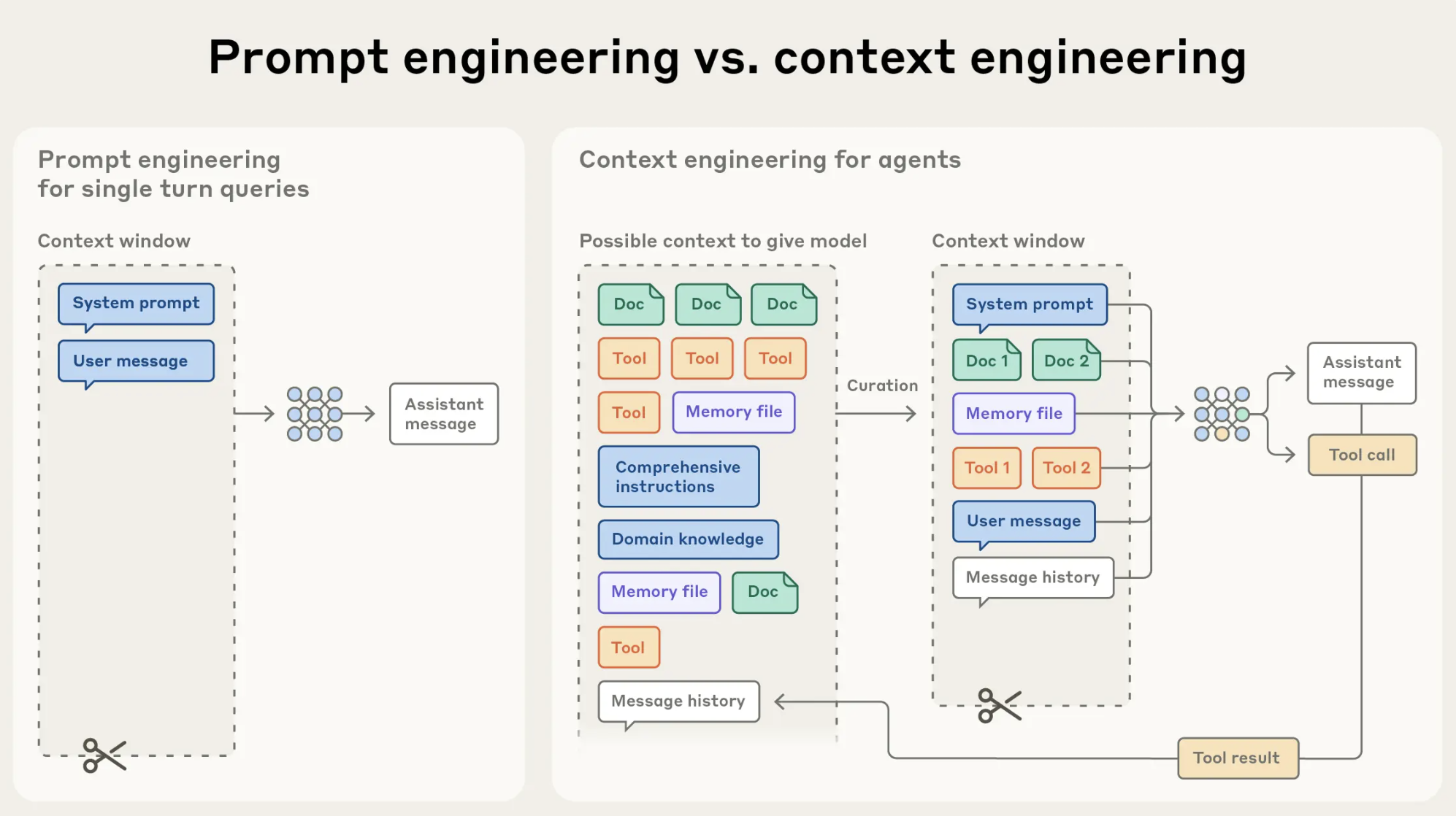
Anthropic’s context engineering (source)
The Four Components Every Agent Prompt Needs
Based on Lilian Weng’s foundational framework for LLM-powered agents and Anthropic’s engineering guidance, a well-designed agent operates on four categories of context. Each one needs deliberate design. Leaving any of them to chance is where most failures originate.
The System Prompt
The system prompt is the brief your agent operates under for the entire task. It defines the role the agent plays, the tools available to it, the constraints it must respect, and the output it should deliver. It is the most consequential piece of text in your entire agent architecture, and it is also the easiest one to write badly.
Anthropic’s engineering team describes two failure modes that bracket the wrong approaches. On one side: over-specification. Prompts packed with brittle if-else logic that try to anticipate every possible scenario, hardcoding behavior that should be left to the model’s judgment. These prompts are fragile — one edge case they did not anticipate, and the whole system misbehaves. On the other side: under-specification. Vague, high-level goals that assume the model shares context it does not have. These prompts leave the agent to fill in blanks you did not know you were leaving.
The right approach is what Anthropic calls the right altitude: specific enough to meaningfully constrain behavior, flexible enough to handle situations you did not explicitly script. Here is what that looks like in practice.
Weak system prompt:
You are a helpful research assistant. Help the user with their research tasks.Strong system prompt:
You are a research assistant helping a B2B SaaS product team synthesize
competitive intelligence. You have access to a web search tool and a
file-writing tool. Your work will be reviewed by a product manager before
any decisions are made.
When given a research task:
1. Clarify the scope if the goal is ambiguous before starting
2. Search for information from primary sources first (company websites,
official announcements, earnings calls) before secondary sources
3. Flag any information older than 12 months as potentially outdated
4. Do not draw conclusions about competitor strategy -- report findings
only and let the human interpret them
Deliver a structured report with: Executive Summary (3-5 sentences),
Findings by category, and a Sources section with URLs. Format as Markdown.The second version does not over-specify every action the agent might take. It gives the agent a clear role context, behavioral constraints, a source priority hierarchy, a scope on what it should and should not conclude, and an output format. Those are heuristics, not scripts, and that is exactly what makes them durable.
Tools
Every tool you give an agent is a decision point and a token cost. Tool descriptions consume attention budget. Overlapping tools create ambiguity. According to Anthropic’s guidance, one of the most common failure modes in production agents is bloated tool sets, where the agent cannot reliably decide which tool to use in a given situation.
The test is simple: if you, as a human looking at the agent’s situation, cannot instantly decide which tool applies, the agent will not reliably decide either. Every tool should have exactly one job, a description that makes its purpose unambiguous, and parameters that are descriptive enough to use without external documentation.
Weak tool description:
{
"name": "search",
"description": "Search for information",
"parameters": {
"query": "string"
}
}Strong tool description:
{
"name": "web_search",
"description": "Search the public web for current information. Use this for factual lookups, recent news, company information, and product details. Do NOT use for internal documents or proprietary data.",
"parameters": {
"query": {
"type": "string",
"description": "A specific search query. Be precise — broad queries return less useful results."
},
"max_results": {
"type": "integer",
"description": "Number of results to return. Default 5. Increase to 10 for broad research tasks."
}
}
}The stronger description tells the agent when to use the tool, when not to use it, and how to use its parameters effectively. That guidance shapes tool selection decisions across every step of execution.
Examples
Few-shot examples inside an agent context serve a different function than they do in standard prompting. In a chatbot context, examples demonstrate the format you want. In an agent context, examples demonstrate reasoning patterns — specifically, how the agent should think through decisions, not just what output it should produce.
The most effective examples for agents show the full reasoning trace: what the agent observed, what it considered, what it decided, and why. This is sometimes called a scratchpad pattern, and it is particularly effective for tasks that involve judgment calls under uncertainty.
Standard few-shot example:
User: Summarize this document.
Assistant: [summary]Agent-appropriate few-shot example:
Task: Research the pricing model for Competitor X.
Thought: I need to find current pricing information. I'll start with their
official website since that's a primary source.
Action: web_search("Competitor X pricing 2024 official")
Result: Found pricing page showing three tiers: Starter ($29/mo),
Professional ($99/mo), Enterprise (custom).
Thought: The pricing page was last updated 8 months ago. I should check
for any recent announcements that might indicate changes.
Action: web_search("Competitor X pricing change announcement 2024")
Result: No relevant announcements found.
Thought: I have primary source data that is 8 months old. I should flag
this in my report as potentially outdated per my instructions.
Output: [structured report with staleness flag included]The second example teaches the agent the reasoning discipline you want it to apply, not just the output format.
Context and State Management
As an agent works through a task, its context window accumulates tool results, intermediate outputs, and reasoning traces. Without deliberate management, this accumulation degrades performance. The agent begins to lose track of early constraints, repeat work it has already done, or get confused by contradictory intermediate outputs.
Effective context management involves several practices. Summarization compresses completed work into compact representations before moving to the next phase, preserving the key findings without preserving every token of the raw output. Selective retention keeps only the information that remains relevant to future steps, discarding intermediate scaffolding once it has served its purpose. State externalization moves persistent information — completed steps, key findings, current task status — out of the context window entirely and into external memory or structured files the agent can query when needed.
These are architectural decisions, not prompt-writing decisions, but they are downstream of how you design your prompts. A system prompt that instructs the agent to maintain a running task log in an external file, for example, is a prompt-level intervention that prevents context bloat from accumulating in the first place.
Reasoning Architectures That Make Agents More Reliable
Beyond the four components, the reasoning pattern you instruct an agent to follow has a large effect on its reliability. Three patterns have the strongest evidence base.
Chain of Thought
Chain of thought prompting, introduced by Wei et al. in 2022, instructs models to reason step by step before producing a final answer. In agent contexts, the value is not just accuracy improvement on individual steps — it is that the reasoning trace becomes auditable. You can read the trace and see exactly where the agent went wrong, which makes debugging and iteration substantially faster.
The instruction is simple to add to any system prompt:
Before taking any action or producing any output, think through your
reasoning step by step. Write out your thought process explicitly.ReAct
ReAct (Reasoning + Acting), introduced by Yao et al. in 2022, interleaves reasoning and action in a structured loop: the agent thinks, acts, observes the result, thinks again, and continues. This is the reasoning pattern that underlies most production agent frameworks, including LangChain’s agent executor and many others.
The key value of ReAct in prompting terms is that it prevents the agent from acting on stale assumptions. Each action is grounded in the most recent observation, so the agent’s plan evolves as it learns from what it finds. Without this structure, agents tend to commit to an early plan and execute it even when intermediate results suggest the plan should change.
ReAct-style instructions in a system prompt:
Follow this loop for every step:
Thought: [reason about the current situation and what to do next]
Action: [the tool call or action you will take]
Observation: [what the tool returned or what you observed]
... repeat until the task is complete, then produce your final output.Reflexion
Reflexion, introduced by Shinn et al. in 2023, extends ReAct by adding an explicit self-evaluation step. After completing a task or reaching a decision point, the agent reflects on whether its output actually satisfies the original goal, identifies gaps or errors, and iterates if needed.
This pattern is particularly valuable for tasks with quality criteria that are hard to specify upfront — writing tasks, analysis tasks, tasks where “good enough” requires judgment. The agent becomes its own first reviewer, catching errors before they surface in the final output.
Reflexion-style instruction:
After completing each major section of work, evaluate your output against
the original task requirements:
- Does this fully address what was asked?
- Are there gaps, errors, or unsupported claims?
- If yes, correct them before proceeding.Where Most Agent Prompts Fail
Understanding the failure modes is as useful as understanding the patterns. The most common ones in practice are:
Ambiguous goal specification. The agent is given a goal that seems clear to the human but contains implicit assumptions the model does not share. The agent fills those gaps with its own inferences, and the task drifts from what was intended. The fix is to specify not just what you want but what constraints bound an acceptable answer — scope, format, sources, what to exclude, what counts as done.
Tool proliferation. Adding tools to an agent feels like giving it more capability. It also increases the cognitive load of tool selection at every step. Agents with many overlapping or ambiguously defined tools make inconsistent tool choices, which compounds across steps. The fix is to audit your tool set ruthlessly: if two tools could plausibly apply to the same situation, either merge them or sharpen their descriptions until the distinction is unambiguous.
Context neglect. Long-running agents accumulate context that degrades their performance. The fix is to treat context management as a first-class design concern, building summarization and state externalization into the agent’s instructions from the start, not retrofitting them after you observe degraded performance.
No recovery path. Many agent prompts specify what to do when things go well and say nothing about what to do when they do not. An agent that encounters an unexpected error, a tool that returns nothing, or a result that contradicts its assumptions needs explicit instructions for how to handle these situations. Without them, it will either stall or proceed on bad data. The fix is to include explicit error-handling instructions: what to do when a tool fails, when a search returns no results, when an intermediate output is incomplete or contradictory.
Putting It Together
The shift from prompt engineering to context engineering is not a rebrand. It reflects a genuine change in what the design problem is. When you are building agents, you are no longer writing a message — you are designing the information environment a system will operate in across many steps, many tool calls, and potentially many minutes or hours of autonomous execution.
The principles that make agents reliable are not complicated, but they require deliberate application. Clear system prompts at the right altitude. Tool sets that are lean and unambiguous. Examples that demonstrate reasoning, not just output. Context management that prevents accumulation from degrading performance. Reasoning architectures — chain of thought, ReAct, Reflexion — that make the agent’s thinking auditable and correctable.
Most agent failures are not model failures. They are design failures in the information environment the model was given to work in. Getting that environment right is the core skill of agentic AI engineering, and it starts with understanding that prompting an agent is a fundamentally different discipline from prompting a chatbot.