ML System Design Interviews: 10 Real Problems Solved
ML system design interviews test more than model choice. This guide walks through 10 real problems covering data, features, serving, and feedback loops.

ML system design interviews test how well you can think beyond models. In these interviews, choosing an algorithm is only one part of the answer. You also need to explain how data is collected, how features are created, how predictions are served, and how the system improves over time.
Most real ML systems are built around product decisions. A feed system decides what to show. A fraud system decides what to block. A search system decides what to rank. This article walks through 10 such problems in a practical interview style.
How to Think in an ML System Design Interview
Start with the product goal. Every ML system is built to make a decision. A feed system decides which post to show. A fraud system decides whether a payment is risky. A search system decides which products should appear first.
Once the goal is clear, define success. Do not only talk about model metrics. A good ML system design answer should cover three types of metrics:
- Model metrics: accuracy, AUC, RMSE, precision, recall, NDCG
- Product metrics: revenue, retention, conversion, fraud loss, user satisfaction
- System metrics: latency, throughput, availability, freshness, cost
Next, discuss the data. Explain what data is collected, how labels are created, and where bias can enter. Some labels are quick, like clicks. Some labels are delayed, like chargebacks, complaints, or product returns.
Then split the system into three views: offline path, online path, and feedback loop.
Offline Path
The offline path is used to prepare data and train the model. It usually runs in batches. It focuses on quality, correctness, and repeatability.
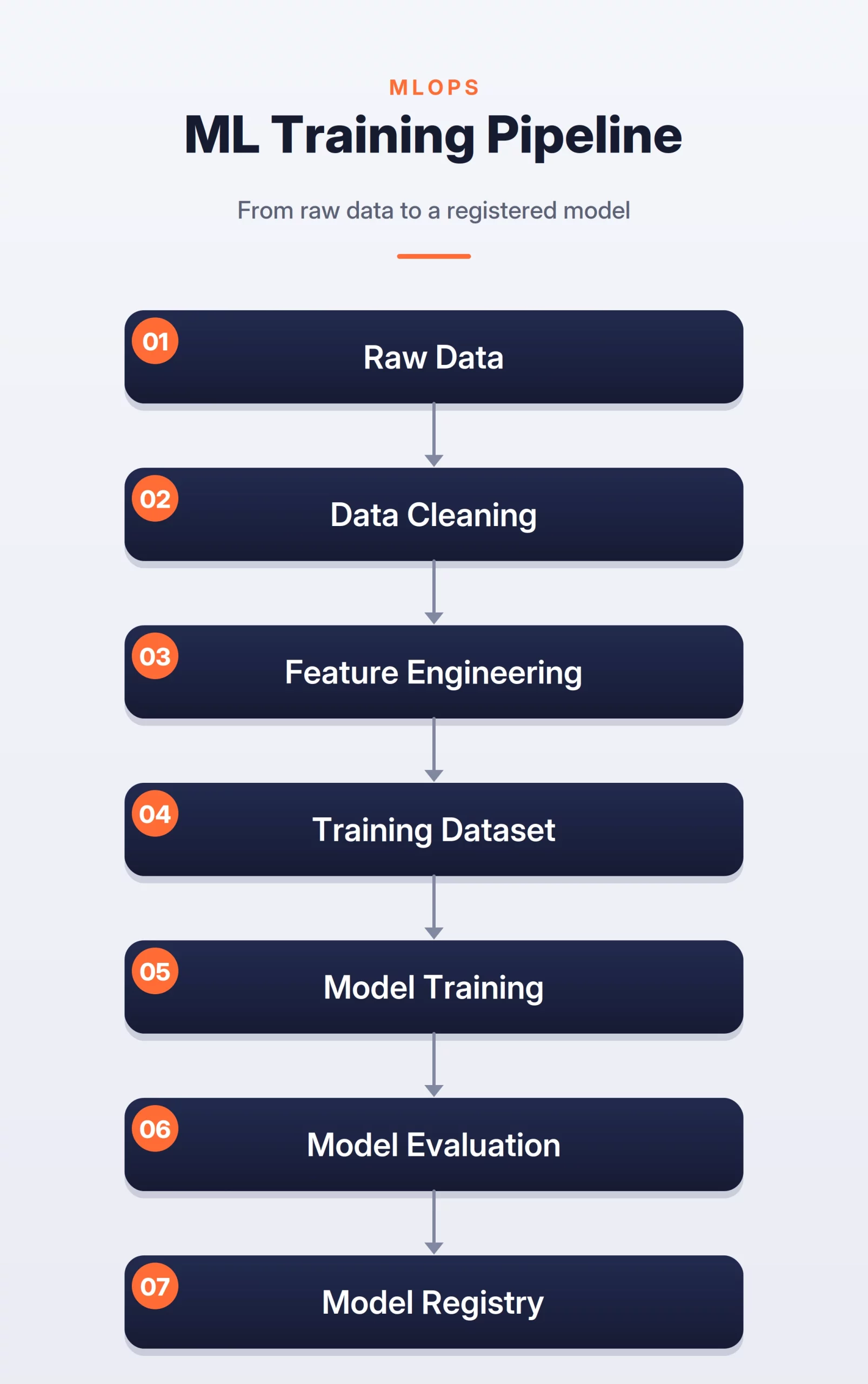
Online Path
The online path is used to serve predictions. It must be fast and reliable because the user is waiting for the result.

ML System Feedback Loop
The feedback loop connects online behavior back to training. This is how the system improves over time.
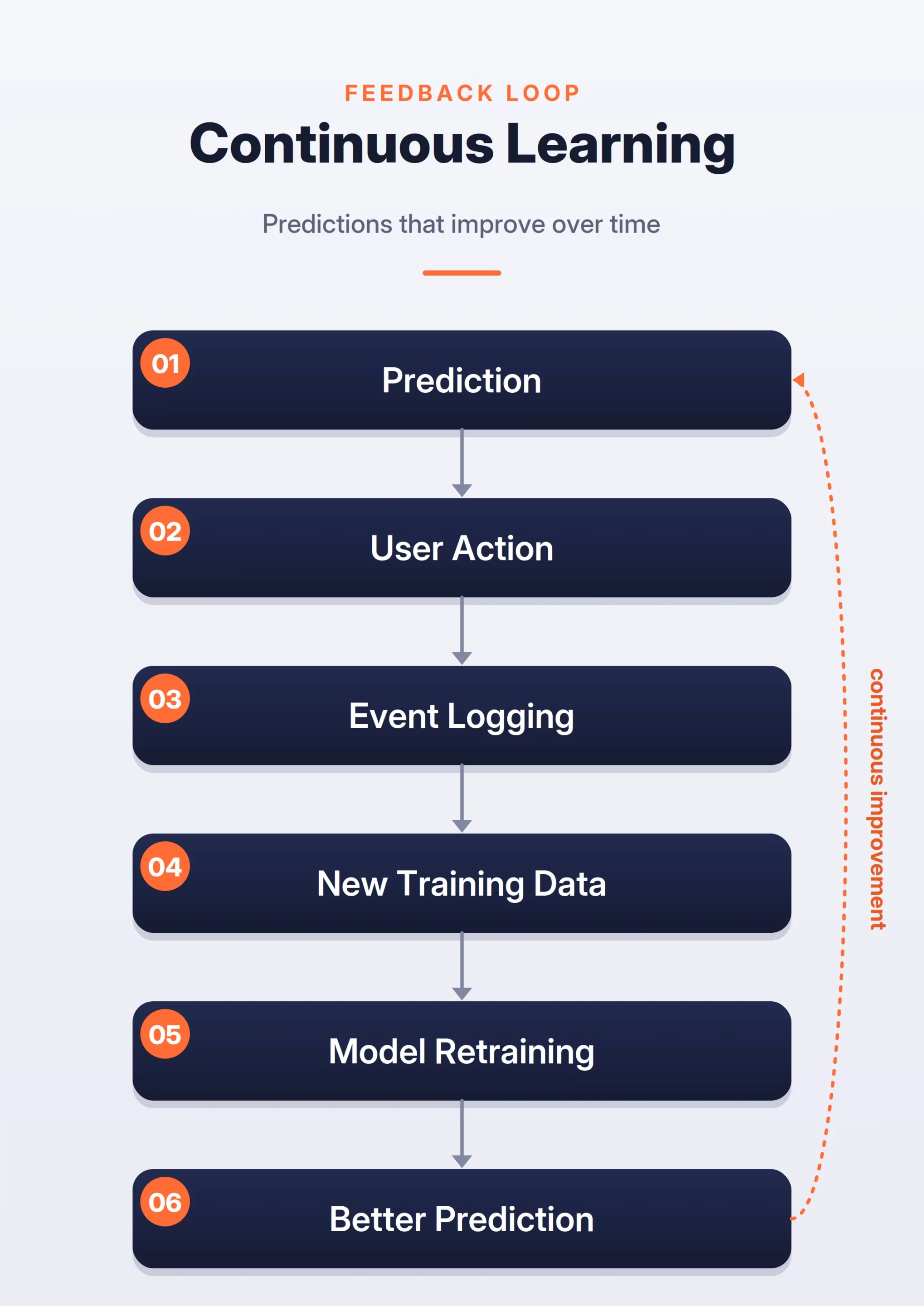
These three diagrams cover the core structure of most ML systems. In an interview, they help you explain the system clearly without jumping directly into algorithms.
1. Feed Ranking System
A feed ranking system decides what a user should see next across social media, short video, news, or networking platforms.
While it may seem like a simple ranking problem, production systems deal with millions of possible posts and can show only a few. So instead of scoring every post, the system first narrows the candidate set, then uses a stronger model to rank the best options.
Problem Statement
Design a personalized feed ranking system. Given a user and a large pool of posts, return a ranked list of posts that the user is likely to find useful or engaging.
The system should handle freshness, personalization, safety, diversity, and low latency.
How the System Works
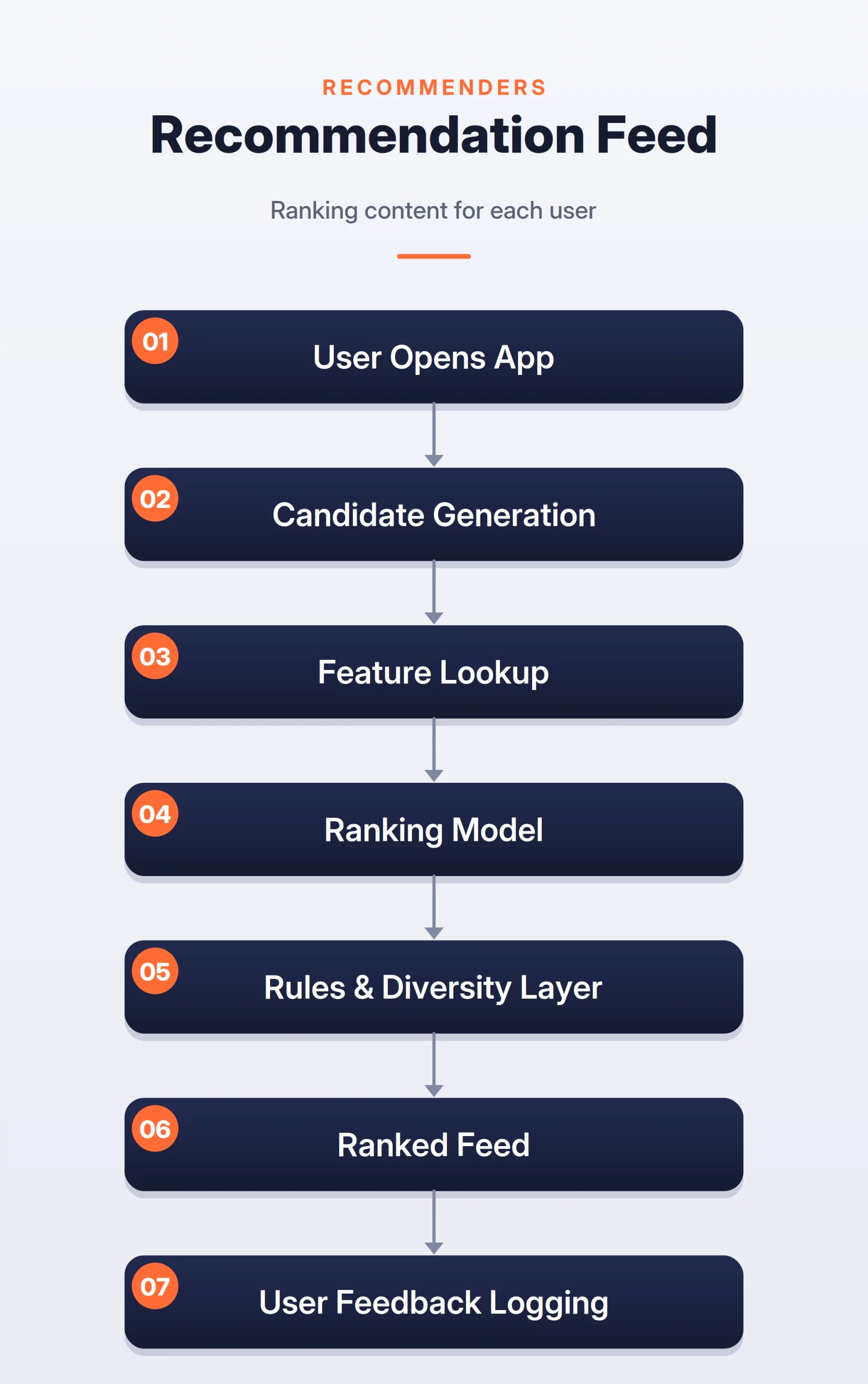
The system usually works in three stages.
- Candidate generation selects a smaller set of posts. These posts can come from people the user follows, topics the user likes, trending content, similar users, or embedding-based retrieval.
- The ranking model scores each candidate. The score can be based on predicted clicks, likes, comments, shares, watch time, skips, or hides. In a real system, the final score is often a weighted mix of many predicted actions.
- A rules layer adjusts the ranked list. It removes unsafe content, avoids duplicates, improves diversity, and prevents the feed from showing too many posts from the same creator.
Feed Ranking Flow
Important Signals
The model needs signals about the user, the post, and the interaction between them.
Useful signals include:
- User interests and past behavior
- Creator affinity
- Post freshness
- Post engagement rate
- Content category
These signals help the model understand both long-term preferences and short-term intent. For example, a user may usually like machine learning content, but in the current session they may be watching more career-related posts.
Model Choice
A good first version can use a gradient boosted tree model. It works well with tabular features and is easier to debug than a complex deep model.
As the system grows, candidate generation can use embeddings. The ranking model can also become more advanced, incorporating deep learning models, sequence models, or multi-task models that predict multiple actions at once.
The important point is to start simple. A strong baseline with good logging is more useful than a complex model that is hard to monitor.
Evaluation Metrics
Offline evaluation can use AUC, NDCG, precision@K, and recall@K. These metrics show whether the model can rank relevant posts higher.
Online evaluation is more important. The system should track click-through rate, dwell time, session length, hide rate, retention, and content diversity.
A feed system should not optimize only for clicks. Clickbait content may increase short-term engagement but harm long-term user satisfaction.
Trade-offs
The biggest trade-off is relevance versus exploration. If the system only shows content similar to past clicks, the feed becomes repetitive. If it explores too much, the user may see irrelevant posts.
There is also a trade-off between freshness and quality. New posts may not have enough engagement data yet. But if the system ignores new posts, users may miss timely content.
Latency is another concern. The system must return the feed quickly. Candidate generation, feature lookup, and ranking should all be optimized for fast response.
2. Ads CTR Prediction System
An ads click-through rate (CTR) prediction system estimates the probability that a user will click on a given ad. This prediction is used to rank ads and determine which ones are shown.
Problem Statement
Design a system that predicts whether a user will click on an ad given the user context, ad content, and placement context. The system must operate at high volume with low latency.
How the System Works
The system estimates P(click | user, ad, context). This probability is used alongside bid price to rank ads in an auction. Higher predicted CTR means the ad is more likely to be shown.
Key stages include:
- Feature engineering: User features (demographics, browsing history, past ad interactions), ad features (category, creative type, historical CTR), and context features (platform, time of day, device).
- Model training: Train on logged impression data with click or no-click labels.
- Serving: At request time, retrieve features from a feature store and score candidate ads in real time.
Important Signals
- User click history on similar ads
- Ad historical CTR
- User-ad relevance (category match)
- Time of day and day of week
- Device type and platform
Model Choice
Logistic regression is a strong baseline for CTR prediction. It is fast, interpretable, and handles sparse features well.
More advanced systems use factorization machines or deep learning models such as Wide & Deep or DeepFM. These models capture feature interactions that logistic regression misses.
Evaluation Metrics
- Offline: Log loss, AUC
- Online: CTR, revenue per impression, advertiser ROI
Trade-offs
Impression data is biased. The model only sees ads that were already shown, so it may underestimate CTR for ads that have never been displayed. Exploration strategies like epsilon-greedy or upper confidence bound (UCB) can help.
Label delay is minimal for clicks, but downstream conversions (purchases, sign-ups) may take hours or days to appear, making conversion-based training harder.
3. E-commerce Search Ranking System
A search ranking system returns a list of products in response to a user query. The goal is to show the most relevant and purchasable products at the top.
Problem Statement
Design a system that ranks products for a search query on an e-commerce platform. The system should balance relevance, personalization, revenue, and freshness.
How the System Works
- Query understanding: Parse and expand the query. Handle typos, synonyms, and intent (navigational vs. exploratory).
- Candidate retrieval: Use inverted indexes or dense retrieval (embeddings) to find matching products.
- Ranking: Score candidates using a learned model. Features include query-product relevance, user purchase history, product popularity, price, and seller quality.
- Business rules: Apply filters for out-of-stock items, sponsored placements, and policy violations.
Important Signals
- Query-product text match (BM25 or embedding similarity)
- User purchase and click history
- Product conversion rate
- Product rating and review count
- Inventory availability
Model Choice
A learning-to-rank model (LambdaMART or LightGBM with ranking objectives) is a strong starting point. It handles tabular features and is easy to evaluate with offline ranking metrics.
Neural ranking models can improve relevance for complex or ambiguous queries by better capturing semantic similarity between the query and product description.
Evaluation Metrics
- Offline: NDCG@K, MRR, precision@K
- Online: Add-to-cart rate, purchase rate, revenue per search, zero-result rate
Trade-offs
Optimizing purely for clicks can surface popular but less relevant items. Optimizing for purchases is better aligned with business goals but introduces label delay.
New products have little engagement data, creating a cold-start problem. Fallback strategies like content-based ranking or popularity-based defaults help bridge this gap.
4. Fraud Detection System
A fraud detection system identifies fraudulent transactions in real time to protect users and the platform from financial loss.
Problem Statement
Design a system that classifies whether a payment transaction is fraudulent. The system must make a decision in milliseconds and handle severe class imbalance, since fraudulent transactions are rare.
How the System Works
- Real-time feature extraction: Pull features about the transaction, the user account, the device, and the merchant within milliseconds.
- Model scoring: Apply a trained model to produce a fraud probability score.
- Decision logic: If the score exceeds a threshold, block or flag the transaction. Some systems route borderline cases to a human review queue.
- Label collection: Fraud labels come from chargebacks, user reports, and manual review. These labels are delayed, sometimes by days or weeks.
Important Signals
- Transaction amount and frequency
- Device fingerprint and IP address
- Location vs. historical location
- Time since account creation
- Merchant category and risk profile
- Velocity features (transactions in the last 1 hour, 24 hours)
Model Choice
Gradient boosted trees (XGBoost, LightGBM) are widely used for fraud detection. They handle mixed feature types, are robust to outliers, and produce well-calibrated scores.
For sequential patterns, recurrent models or transformer-based sequence models can capture behavioral patterns over time.
Evaluation Metrics
- Offline: AUC, precision-recall curve, F1 at operating threshold
- Online: Fraud loss prevented, false positive rate (legitimate transactions blocked), chargeback rate
Trade-offs
Class imbalance is severe. Fraud may represent less than 0.1% of transactions. Techniques like oversampling, undersampling, and cost-sensitive learning help the model focus on rare fraud cases.
False positives are costly. Blocking a legitimate transaction damages user trust. The threshold must be tuned to balance fraud prevention against user experience.
Fraudsters adapt. The model must be retrained frequently as new fraud patterns emerge.
5. ETA Prediction System
An ETA (estimated time of arrival) prediction system estimates how long a delivery or ride will take. It powers delivery apps, ride-hailing platforms, and logistics systems.
Problem Statement
Design a system that predicts delivery or ride arrival time. The prediction should be accurate at booking time and update continuously as conditions change.
How the System Works
- Route estimation: Compute the likely route using a maps API or internal routing engine.
- Feature extraction: Pull features for each route segment, including historical travel time, current traffic, time of day, weather, and special events.
- Model prediction: Predict total time by combining segment-level predictions or using an end-to-end model.
- Live updates: Recompute ETA as the driver moves and conditions change.
Important Signals
- Historical travel time for each road segment
- Real-time traffic speed data
- Time of day and day of week
- Weather conditions
- Number of stops (for delivery)
- Driver behavior patterns
Model Choice
Gradient boosted trees work well for tabular route features. Graph neural networks can model road network structure. Sequence models handle the time-varying nature of traffic.
For multi-stop delivery, combinatorial optimization techniques determine stop order before the ML model predicts each segment’s travel time.
Evaluation Metrics
- Offline: MAE, RMSE, percentage within a time window (e.g., within ±5 minutes)
- Online: On-time delivery rate, user rating, cancellation rate due to long ETA
Trade-offs
ETA at booking time is uncertain. Confidence intervals or percentile-based estimates help set user expectations more accurately than a single point estimate.
There is a feedback loop risk. If ETA is too optimistic, drivers rush. If too pessimistic, users cancel. The model must be calibrated carefully.
6. Spam and Phishing Detection System
A spam and phishing detection system classifies incoming messages, emails, or URLs as harmful or safe to protect users from malicious content.
Problem Statement
Design a system that detects spam emails and phishing attempts. The system should work in real time, generalize to new attack patterns, and minimize false positives on legitimate messages.
How the System Works
- Content extraction: Parse the email or message for text, links, attachments, and metadata.
- Feature engineering: Create features from sender reputation, URL patterns, text content, header fields, and embedded images.
- Model scoring: Apply a classifier to produce a spam or phishing probability.
- Action: Block, quarantine, or flag the message based on the score and threshold.
Important Signals
- Sender domain and IP reputation
- Presence of known phishing URLs
- Text patterns (urgency language, impersonation keywords)
- HTML structure and image-to-text ratio
- User complaint history for the sender
Model Choice
A gradient boosted tree model is a strong baseline for tabular features. For text content, fine-tuned transformer models (BERT variants) improve detection of novel phishing language.
A two-stage approach works well: fast rule-based filtering followed by a slower ML model for borderline cases.
Evaluation Metrics
- Offline: Precision, recall, F1, AUC
- Online: User-reported spam rate, false positive rate on legitimate mail, phishing click rate
Trade-offs
Adversarial adaptation is the core challenge. Spammers modify messages to evade detection. The model must be retrained frequently and monitored for distribution shift.
False positives block legitimate email, which damages user trust. The system needs a user feedback mechanism to recover misclassified messages.
7. Visual Defect Detection System
A visual defect detection system identifies defects in manufactured products using images or video, replacing or augmenting manual inspection.
Problem Statement
Design a system that detects visual defects on a production line. The system should work in real time, generalize to unseen defect types, and minimize missed defects while controlling false alarm rates.
How the System Works
- Image capture: Cameras capture images of each product at inspection points on the line.
- Preprocessing: Images are resized, normalized, and augmented for training.
- Model inference: A computer vision model classifies the image as defective or non-defective, or localizes the defect using object detection.
- Action: Flag defective items for removal or route them for manual review.
Important Signals
- Pixel-level image features
- Defect type labels (scratch, dent, discoloration, missing component)
- Product category and expected appearance
- Camera angle and lighting conditions
Model Choice
Convolutional neural networks (CNNs) such as ResNet or EfficientNet are strong baselines for image classification. For defect localization, object detection models like YOLO or Faster R-CNN can identify defect location and type simultaneously.
For rare defects with few labeled examples, anomaly detection approaches (training only on normal images and flagging deviations) are effective.
Evaluation Metrics
- Offline: Precision, recall, F1, mAP (for detection)
- Online: Defect escape rate (missed defects reaching customers), false alarm rate, inspection throughput
Trade-offs
Defect data is imbalanced. Defective products are rare on a healthy production line. Data augmentation, synthetic defect generation, and anomaly detection help address this.
Lighting and camera angle variation can degrade model performance. Consistent hardware setup and preprocessing pipelines reduce this variance.
8. Demand Forecasting System
A demand forecasting system predicts future product demand to optimize inventory, staffing, and supply chain decisions.
Problem Statement
Design a system that forecasts product demand at a daily or weekly level across multiple locations. The system should account for seasonality, trends, promotions, and external events.
How the System Works
- Data collection: Gather historical sales data, promotional calendars, pricing data, and external signals like weather and holidays.
- Feature engineering: Create time-based features (day of week, month, week number), lag features, rolling averages, and event indicators.
- Model training: Train a forecasting model for each product-location combination, or use a global model that handles multiple series.
- Forecast generation: Produce point forecasts or probabilistic forecasts for each product over the forecast horizon.
Important Signals
- Historical sales volume
- Day of week, month, and seasonality
- Price and promotion history
- Local events and holidays
- Weather (for weather-sensitive products)
- Inventory availability (stockouts distort observed demand)
Model Choice
Classical models like ARIMA and Exponential Smoothing are interpretable and work well for stable series. Gradient boosted trees (LightGBM) handle large feature sets and multiple series efficiently.
Deep learning models like N-BEATS, Temporal Fusion Transformer, and DeepAR capture complex patterns and work well when many related series are available for joint training.
Evaluation Metrics
- Offline: MAE, RMSE, MAPE, WAPE, bias
- Online: Stockout rate, overstock cost, forecast accuracy at each horizon
Trade-offs
Stockout periods distort training data. When a product is out of stock, observed sales underestimate true demand. Demand imputation techniques help correct this.
Forecasting at long horizons (weeks to months) is less accurate than short-horizon forecasts. Communicating forecast uncertainty through prediction intervals helps downstream planners make better decisions.
9. Dynamic Pricing System
A dynamic pricing system adjusts product or service prices in real time based on demand, supply, competition, and user behavior.
Problem Statement
Design a system that recommends optimal prices for products or services. The system should maximize revenue or profit while maintaining acceptable conversion rates and user fairness.
How the System Works
- Demand estimation: Model how demand changes with price using historical sales data at different price points.
- Price optimization: Given the demand model, find the price that maximizes expected revenue or profit.
- Constraints: Apply business rules such as minimum and maximum price bounds, competitor price tracking, and fairness constraints.
- Feedback: Observe actual sales at the recommended price and update the demand model.
Important Signals
- Historical price and sales volume pairs
- Competitor prices
- Inventory level and remaining capacity
- User segment and willingness to pay
- Time to event (for tickets, hotels, flights)
- Demand seasonality
Model Choice
Price elasticity models estimate how demand responds to price changes. These can be fit using regression on historical data.
Reinforcement learning is used in more advanced systems, where the pricing agent learns an optimal policy by interacting with the market over time. Contextual bandits offer a middle ground — faster to train than full RL but still adaptive.
Evaluation Metrics
- Offline: Demand model accuracy, revenue simulation
- Online: Revenue per unit, conversion rate, price competitiveness, user complaint rate
Trade-offs
Causal identification is the core challenge. Observational data confounds price and demand because prices are not set randomly. Natural experiments, A/B testing on prices, and instrumental variable methods help estimate true price elasticity.
Perceived fairness matters. If users notice that prices change frequently or differ across segments, it can damage trust and trigger regulatory scrutiny.
10. RAG-Based Customer Support Assistant
A retrieval-augmented generation (RAG) system answers customer support questions by combining a language model with a knowledge base of product documentation, policies, and FAQs.
Problem Statement
Design a customer support assistant that answers user questions accurately using company knowledge. The system should minimize hallucinations, handle out-of-scope questions gracefully, and escalate to a human agent when needed.
How the System Works
- Knowledge base construction: Index product documentation, FAQs, policies, and past resolved tickets into a vector store.
- Query encoding: Encode the user question using an embedding model.
- Retrieval: Find the most relevant documents using approximate nearest neighbor search.
- Generation: Pass the retrieved documents and the user question to a language model. The model generates a response grounded in the retrieved context.
- Safety and escalation: Filter responses for harmful content, detect low-confidence answers, and route complex cases to human agents.
Important Signals
- Query-document embedding similarity
- Document recency and authority
- User intent classification (billing, technical, returns)
- Confidence score of the generated response
- Past resolution success rate for similar queries
Model Choice
The retrieval component can use dense embeddings from models like Sentence-BERT or OpenAI’s embedding API, combined with a vector database such as FAISS, Pinecone, or Weaviate.
The generation component can use an instruction-tuned language model (GPT-4, Claude, or a fine-tuned open-source model). Fine-tuning on company-specific support data improves tone and accuracy.
Evaluation Metrics
- Offline: Retrieval recall@K, answer faithfulness, answer relevance, hallucination rate
- Online: Resolution rate, escalation rate, user satisfaction score (CSAT), average handle time
Trade-offs
Hallucination is the primary risk. The language model may generate plausible but incorrect answers. Grounding responses strictly in retrieved documents and adding a verification step reduces this risk.
Knowledge base staleness causes errors. When policies or products change, the knowledge base must be updated promptly. A document versioning and re-indexing pipeline is essential.
Out-of-scope queries must be handled gracefully. If the system cannot find a relevant document, it should acknowledge the limitation and escalate rather than generate a guess.
Final Interview Checklist
Before finishing your answer in an ML system design interview, verify that you have covered the following:
- Product goal: What decision does the system make, and what business metric does it optimize?
- Data: What data is collected, how are labels created, and what are the delay and bias risks?
- Features: What signals does the model use, and how are they computed and served?
- Model: What algorithm is used, why is it appropriate, and what is the baseline?
- Offline evaluation: What metrics are used to validate the model before deployment?
- Online evaluation: What metrics are tracked in production, and how is A/B testing structured?
- Serving: How are predictions served, and what are the latency and throughput requirements?
- Feedback loop: How does the system collect new labels and retrain over time?
- Failure modes: What happens when the model degrades, data is missing, or the system is under load?
- Trade-offs: What design decisions involve explicit trade-offs, and how did you reason about them?
Covering these points consistently across different problem types demonstrates the structured thinking that distinguishes strong ML system design candidates.