Harness-1: A Compact Retrieval Agent That Separates Search from State
Harness-1 separates query generation from state tracking to build a leaner retrieval agent. It outperforms larger systems across eight benchmark domains.

Most search agents try to handle too many jobs at once. They generate new queries, remember what they have already explored, collect evidence, and decide what is relevant as the search keeps expanding. That can make the whole process messy, expensive, and hard to control.
Harness-1 takes a simpler approach. Built with researchers from UIUC, UC Berkeley, and Chroma, it separates the work of finding search terms from the work of tracking search progress. The result is a compact retrieval agent that feels easier to reason about and performs far above what its size might suggest.
In this article, we take a closer look at Harness-1 and why its approach to retrieval agents matters.
Why Existing Search Agents Plateau
Most retrieval agents are trained end to end. The model produces queries, reads chunks, decides what matters, and keeps all that context in a growing transcript. The policy learns everything — search strategy, evidence tracking, deduplication, and stopping conditions.
The problem is reinforcement learning then tries to improve all of this at once. Semantic search decisions like “should I search for ‘merger date’ or ‘acquisition year’?” get tangled with low-level bookkeeping such as “have I seen this chunk before?” RL ends up optimizing both, and they don’t share the same learning dynamics.
The researchers call this the core design flaw. Their fix is clean: move state management out of the model and into a harness.
What the Harness Actually Does
The stateful harness is the main breakthrough. It runs the model as a state machine and maintains four persistent structures throughout each episode:
- A candidate pool consisting of all compressed, deduplicated documents from all candidate searches.
- A curated set — the final output with up to 30 documents identified with importance flags (
very_high,high,fair,low). - A full-text store containing every piece of retrieved data, stored outside the model prompt.
- An evidence graph — a collection of auto-extracted entities, their bridge documents, and singleton leads.
The evidence graph is particularly clever. A regex extractor scans each piece of retrieved data for proper nouns, years, and dates. Bridge documents containing two or more frequently co-occurring entities are flagged as very high priority. Singletons mark potential follow-up searches. At each turn, the harness presents this information in a compact, efficient format.
The Eight-Tool Interface
Every turn, the model emits exactly one action from an eight-tool interface.
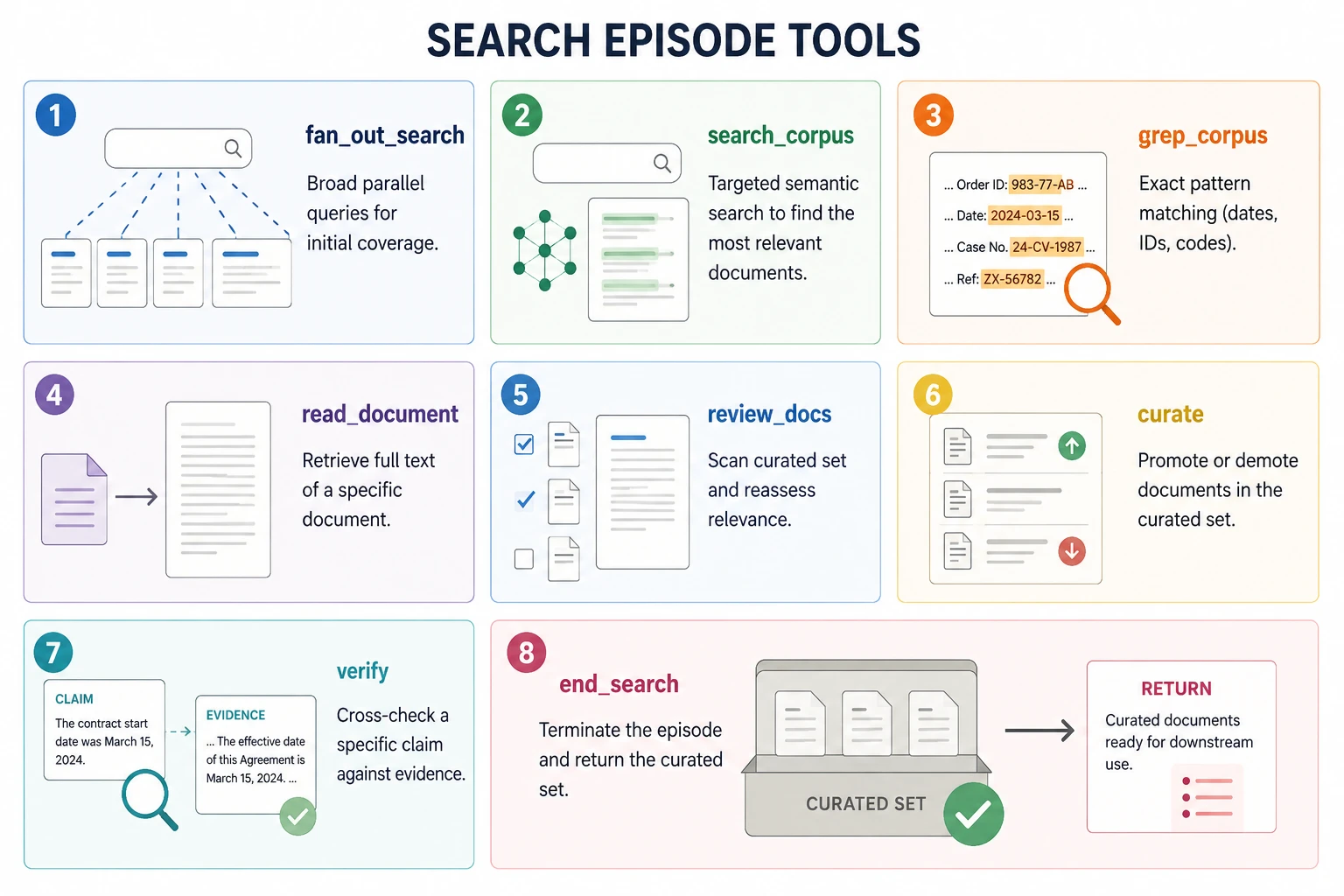
Two-phase compression is applied to the output from the search phase of retrieval. The first phase uses Sentence-BM25 to rank all sentences and select the top 4 from each chunk. The second phase applies two-level deduplication: first by chunk ID, then by content fingerprint. The policy never sees the raw retrieval output before deduplication completes.
This keeps the model’s context clean — it processes only signals, not noise.
The Cold Start Problem and Its Solution
The first challenge in retrieval training is teaching a policy to build a curated dataset from nothing. In the early RL episodes, the policy has no prior to refine from, so it either throws everything into the curated set or curates nothing at all.
Harness-1 addresses this with warm-start seeding. After the harness performs a search for the first time, it automatically generates a curated set using the top 8 reranked results tagged with a fairness rating. This gives the policy a refinement task — improving the quality of existing results — rather than a creation task. The change produces a significant gain in training stability, and demonstrates that curation is learned more easily through refinement than through creation from scratch.
How Training Works: SFT Then RL
The training pipeline has two stages that do different kinds of work.
Stage 1: Supervised Fine-Tuning
A teacher model (GPT-5.4) runs inside the full harness on a large, diverse set of queries. After filtering out poorly performing trajectories, 899 episodes remained — covering correct tool calls, action structure, and curated set updates. These episodes teach the student model the basics of the interface.
# LoRA configuration for SFT
lora_config = {
"rank": 32,
"target_modules": ["q_proj", "v_proj"],
"base_model": "gpt-oss-20b",
"epochs": 3,
"checkpoint_for_rl": 550, # step-550 initializes RL training
}Stage 2: Reinforcement Learning
The second stage uses on-policy CISPO with a terminal-only reward function and a cap of 40 turns. Training data consisted of SEC financial document queries, but the policies generalized to all eight benchmark domains. The reward function offers two key benefits:
- Separation of discovery and selection. Finding a relevant document and curating it are rewarded independently.
- A diversity bonus for tool usage. This bonus matters more than it might seem.
Without the diversity bonus, the agent gets stuck in a loop — repeatedly issuing the same query in slightly varied forms, filling the curated set with similar items, and stalling at 0.53 curated recall. Adding the diversity bonus encourages use of grep_corpus, verify, and read_document alongside search_corpus, pushing recall to 0.60.
# Simplified reward structure
def compute_reward(episode):
discovery_score = count_newly_found_relevant_docs(episode)
selection_score = curated_recall(episode.final_curated_set)
diversity_bonus = tool_diversity_score(episode.action_sequence)
# Terminal reward only - no intermediate shaping
return selection_score + 0.3 * discovery_score + 0.2 * diversity_bonusHands-On: Running Harness-1 Locally
Prerequisites: This repo uses uv for dependency management and vLLM for serving. You will need enough GPU VRAM to run a 20B model — a single A100 (80 GB) works well, or two A100s (40 GB each) using tensor parallelism.
1. Clone the repository and install dependencies.
git clone https://github.com/pat-jj/harness-1.git
cd harness-1
# If you haven't installed uv, do it now
pip install uv
# Pull all dependencies including vLLM
uv sync --extra vllmThe --extra vllm flag pulls in vLLM and its CUDA dependencies, which may take some time on first install. Skipping this step will prevent the inference script from running.
2. Start the model server.
The first run downloads approximately 40 GB of weights from HuggingFace and starts a local OpenAI-compatible server via uvicorn at http://0.0.0.0:8000.
uv run python inference/vllm_local_inference.py serve \
--model pat-jj/harness-1 \
--served-model-name harness-1If you have two GPUs, add --tensor-parallel-size 2 to split the model across both. Without this flag, a single 40 GB GPU will run out of memory.
3. Issue a search request.
Once the server is running, you can send search requests directly to the Harness-1 endpoint. Requests must be formatted as structured queries directed against a Chroma corpus.
Benchmark Results: Where It Stands
Harness-1 was evaluated across eight retrieval benchmark domains. Despite being based on a 20B parameter model, it competes with and in several cases outperforms significantly larger systems, particularly on multi-hop and evidence-intensive queries where clean state management provides the greatest advantage.
What Harness-1 Doesn’t Do
Harness-1 is purpose-built for retrieval. It does not generate final answers, synthesize documents into prose, or act as a general-purpose reasoning agent. It is designed to hand off a clean, prioritized curated set to a downstream component — whether that is a reader model, a RAG pipeline, or a human analyst.
Conclusion
Harness-1 demonstrates that separating state management from the policy model is a practical and effective design choice for retrieval agents. By offloading bookkeeping to a stateful harness, the model can focus on the semantic decisions that actually require learned reasoning. The result is a smaller, more controllable system that generalizes well beyond its training domain — and a useful reminder that architectural clarity can matter as much as scale.
Frequently Asked Questions
Q: What is the harness in Harness-1? The harness is a stateful wrapper that runs around the model. It maintains the candidate pool, curated set, full-text store, and evidence graph so the model does not have to track any of this in its context window.
Q: What base model does Harness-1 use?
Harness-1 is built on gpt-oss-20b, fine-tuned with LoRA during SFT and further trained with on-policy RL using CISPO.
Q: Why does the diversity bonus matter so much in RL training?
Without it, the agent defaults to repeating search_corpus calls with minor query variations. The bonus incentivizes use of complementary tools like grep_corpus, verify, and read_document, which breaks the loop and improves recall from 0.53 to 0.60.
Q: What hardware do I need to run Harness-1 locally? You need a GPU with at least 80 GB of VRAM (one A100 80 GB) or two GPUs with 40 GB each using tensor parallelism. The model weights are approximately 40 GB.