GraphRAG vs Vector RAG: A Practical Comparison for Retrieval Systems
GraphRAG and Vector RAG serve different retrieval needs. This guide breaks down their architectures, query handling, and when to use each.
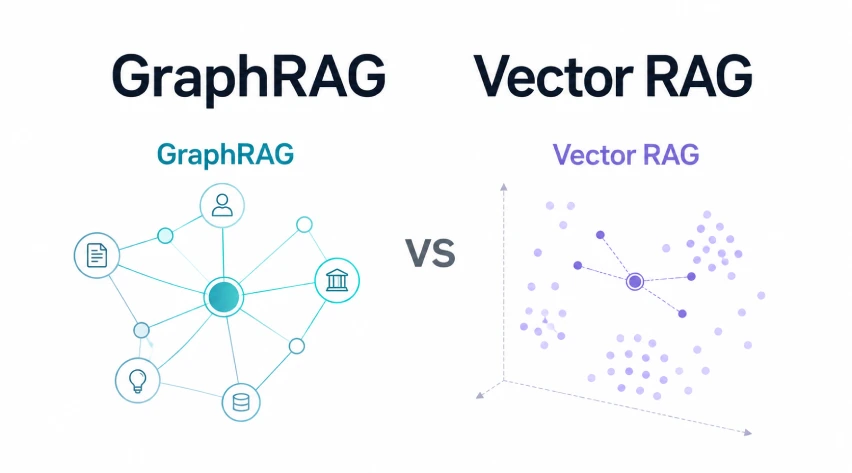
GraphRAG and Vector RAG address different retrieval needs. Vector RAG splits documents into chunks, embeds them, retrieves semantically similar passages, and sends them to an LLM. It is simple, fast to build, and works best when answers sit within one or two relevant chunks.
GraphRAG adds structure by extracting entities, relationships, and communities, making it stronger for multi-hop reasoning, explainability, and corpus-wide synthesis across connected ideas. In this article, we break down where each approach fits best.
Definitions and Architecture
Vector RAG works by splitting documents into small text chunks. Each chunk is converted into an embedding and stored in a vector database. When a user asks a question, the question is also converted into an embedding. The system then finds the most similar chunks and sends them to the LLM to generate an answer.
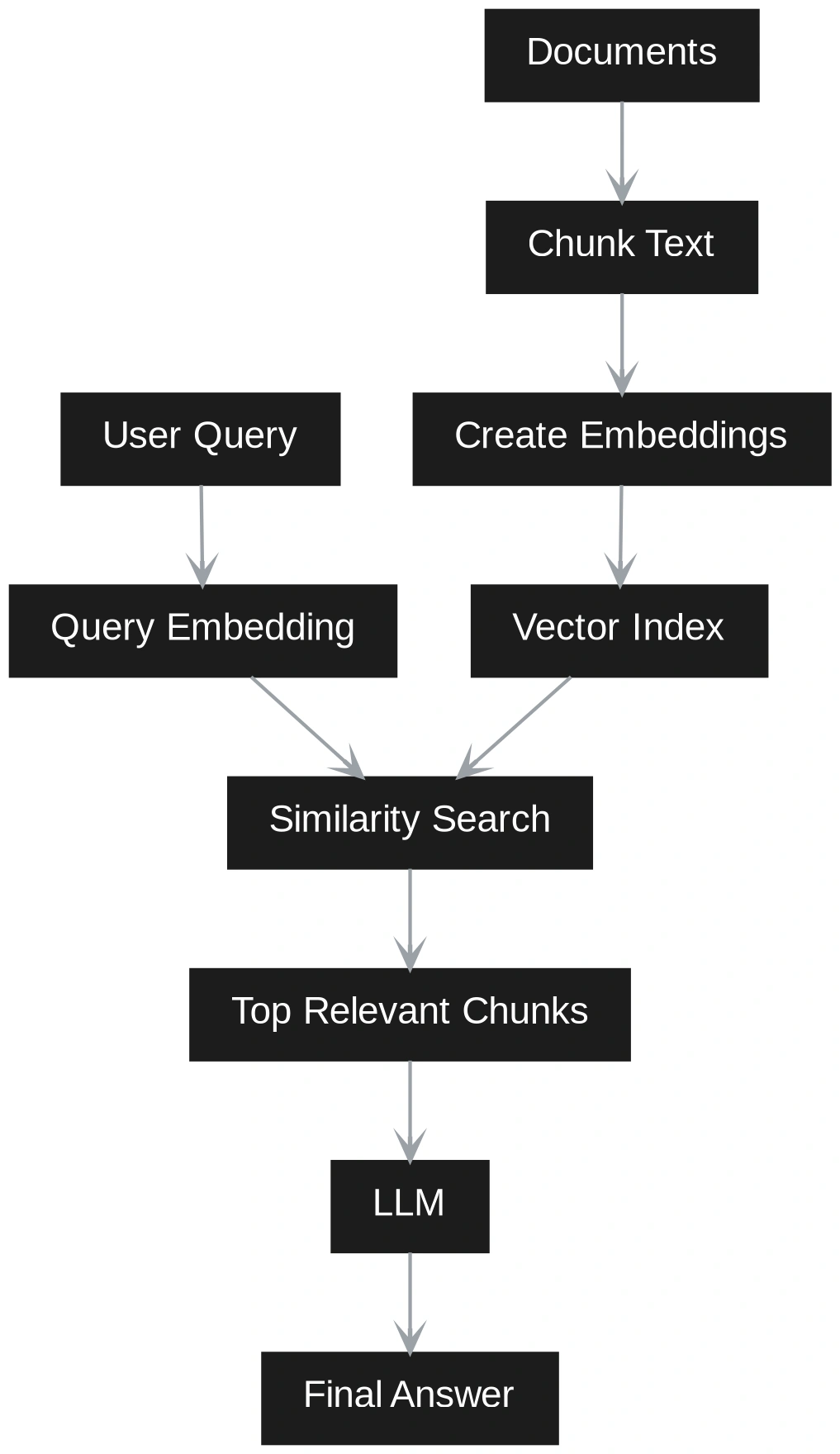
Vector RAG is simple, fast, and easy to update. It works well for direct factual questions. But it stores meaning mostly through embeddings and text, not through explicit entities or relationships. Because of this, it can struggle with questions that need connections across multiple chunks.
GraphRAG adds more structure. It extracts entities, relationships, claims, and communities from the documents. It then builds a graph that shows how different pieces of information are connected.
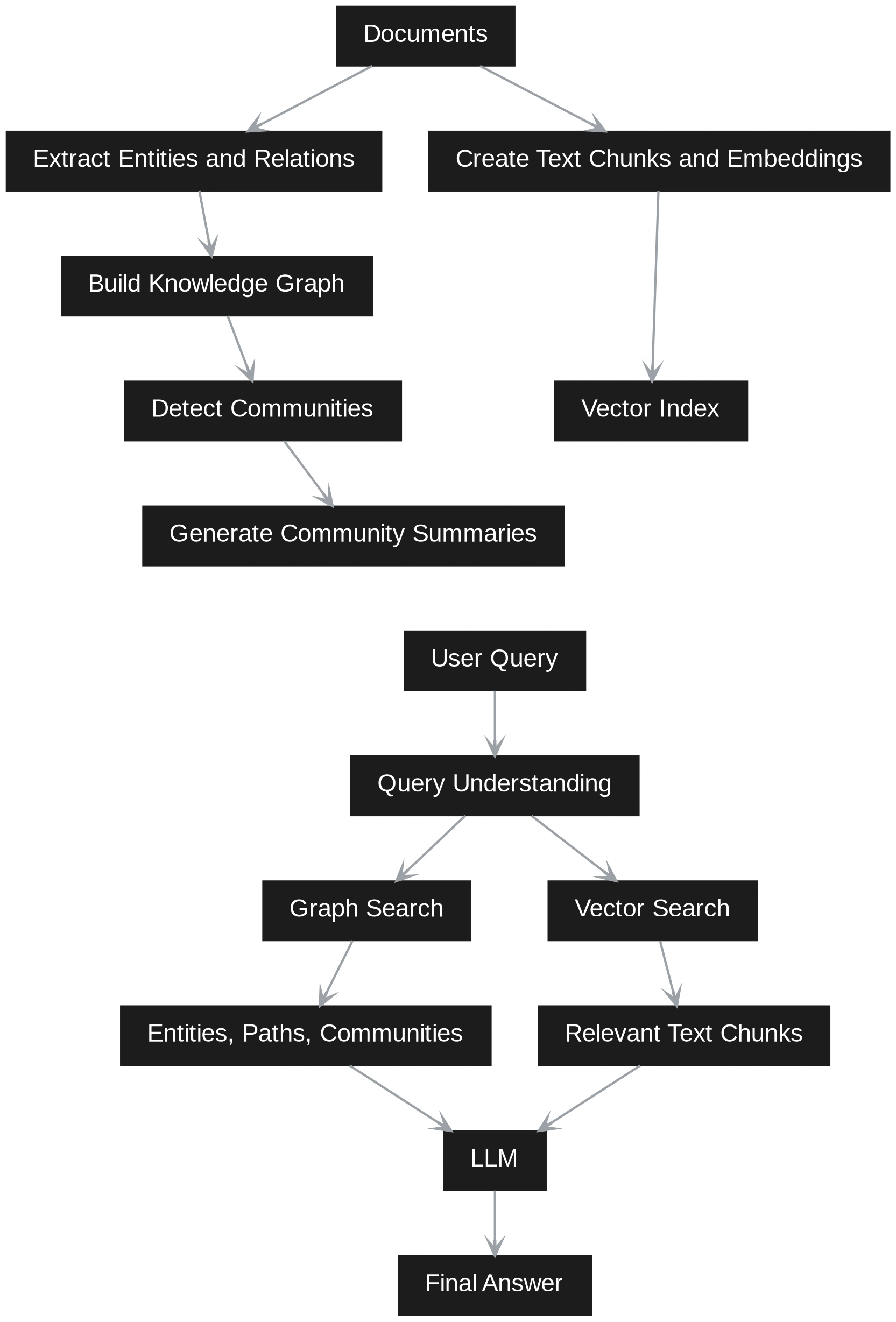
This makes GraphRAG better for relationship-based questions, multi-step reasoning, and broad understanding across a large set of documents. The tradeoff is that it takes more effort and cost to build because it needs graph construction, community detection, and summarization.
In practice, many systems use both. Vector search quickly finds relevant text, while graph retrieval adds connected context and better reasoning.
How Retrieval Works at Query Time
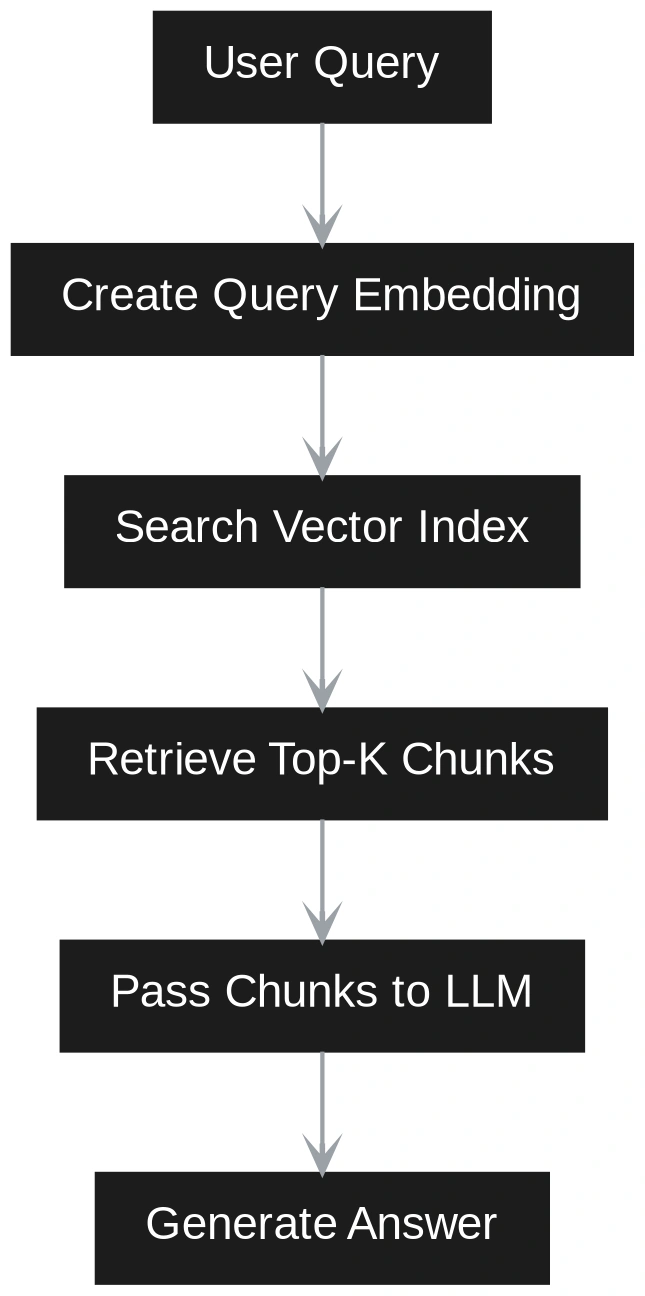
The biggest difference between Vector RAG and GraphRAG becomes clear at query time. In Vector RAG, the query is treated as a semantic search problem. The user question is converted into an embedding. The system compares this query embedding with stored chunk embeddings. It retrieves the closest chunks and sends them to the LLM. The LLM then answers using only those chunks as context. This works well when the answer is directly available in a small set of similar passages.
GraphRAG handles the query differently. It first tries to understand whether the question is local or global. A local question is about a specific entity, event, customer, product, or document. A global question asks for themes, patterns, risks, summaries, or relationships across the corpus.
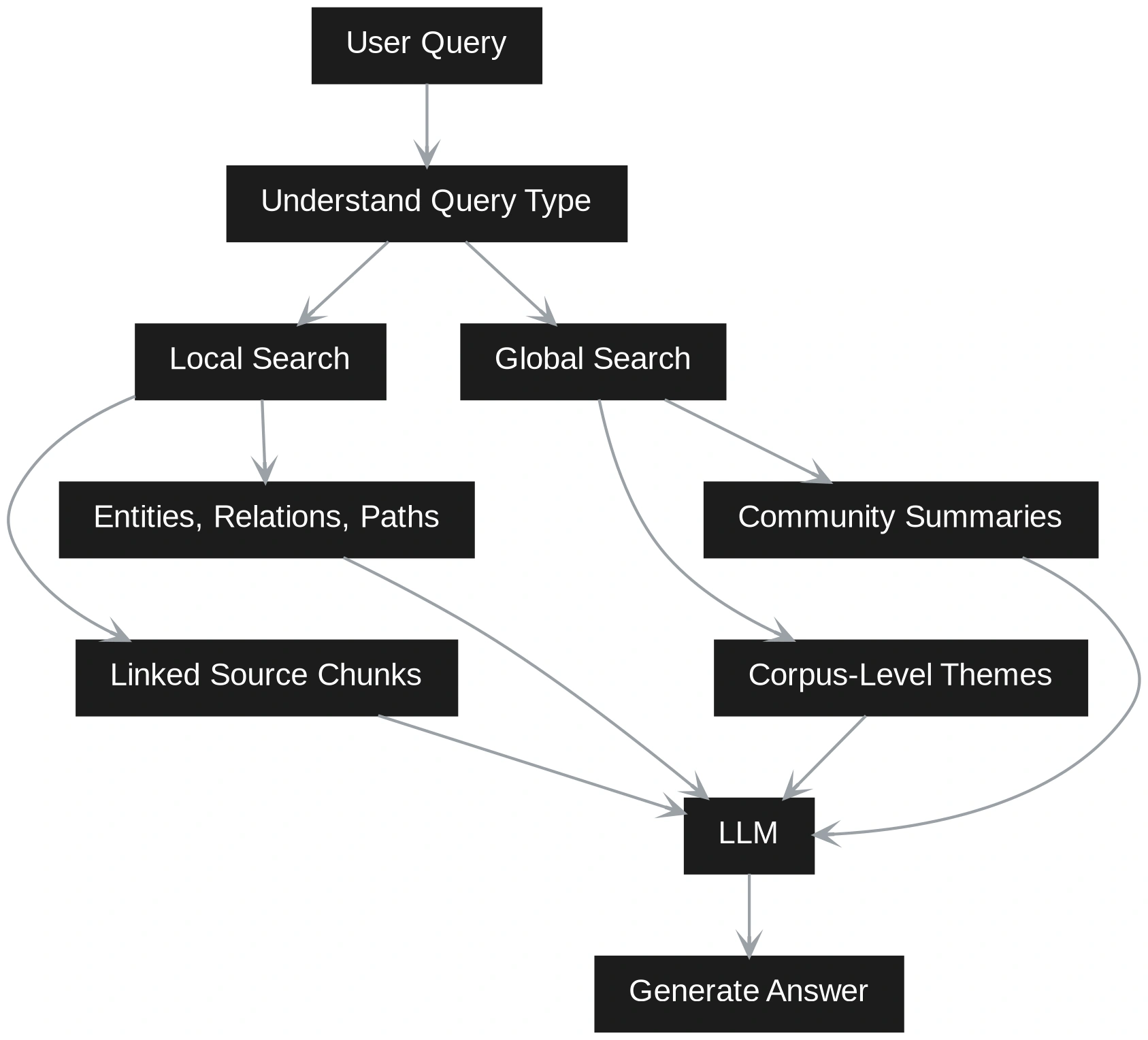
This means Vector RAG retrieves by similarity, while GraphRAG retrieves by structure and meaning together. Vector RAG is faster and easier when the question is narrow. GraphRAG is stronger when the answer depends on connections across many documents. A hybrid system can use both paths — first retrieving relevant chunks through vector search, then expanding the context using graph relationships. This gives the LLM both textual evidence and structured grounding.
Hands-on: Build Vector RAG and GraphRAG from Start to End
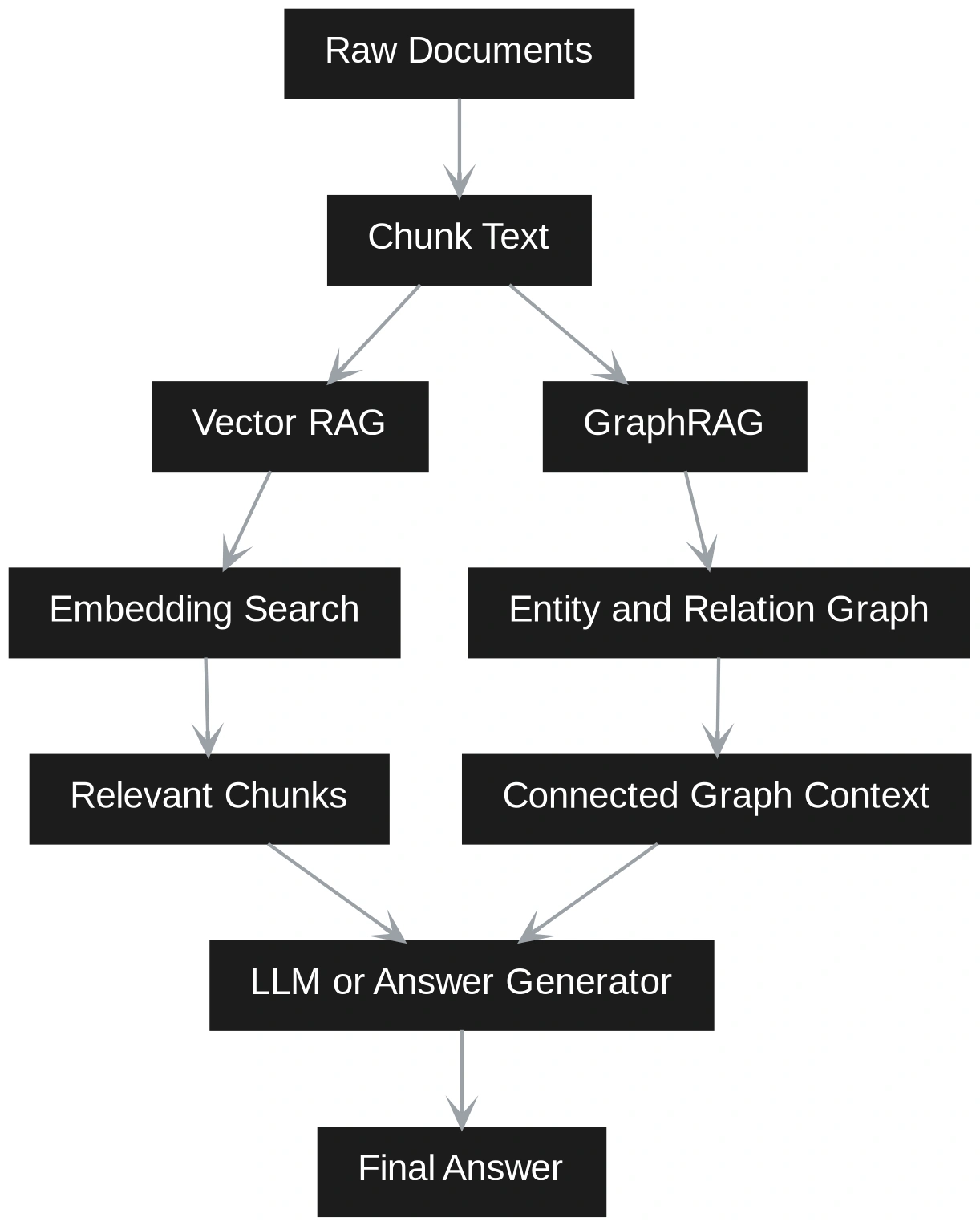
In this hands-on section, we will build both Vector RAG and GraphRAG on the same small corpus. The goal is to show how Vector RAG retrieves similar text chunks, while GraphRAG retrieves entities, relationships, and connected context. We will use Python, SentenceTransformers for embeddings, FAISS for vector search, and NetworkX for graph storage and traversal. SentenceTransformers supports encoding text into embeddings, FAISS is built for efficient vector similarity search, and NetworkX stores graphs as nodes and edges with attributes.
First, install the required libraries.
pip install sentence-transformers faiss-cpu networkx pandas numpyNow create a small demo corpus. This corpus is intentionally small so the difference is easy to show.
docs = [
{
"id": "doc1",
"text": "NourishCo is facing rising logistics costs in its North region. The operations team believes the issue is linked to poor demand forecasting.",
},
{
"id": "doc2",
"text": "The North region uses Vendor A for cold chain delivery. Vendor A has repeated delivery delays during high-demand weeks.",
},
{
"id": "doc3",
"text": "The analytics team proposed a machine learning forecasting model to reduce stockouts and improve supply planning.",
},
{
"id": "doc4",
"text": "The finance team is concerned that Vendor A delays are increasing working capital pressure because inventory buffers are rising.",
},
{
"id": "doc5",
"text": "The leadership team wants an AI roadmap that connects demand forecasting, logistics optimization, and vendor performance monitoring.",
},
]Now define a simple chunking function. In this demo, each document is already short, so we treat each document as one chunk.
chunks = []
for doc in docs:
chunks.append({
"chunk_id": doc["id"],
"text": doc["text"],
})
print(chunks)Now build the Vector RAG index.
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
model = SentenceTransformer("all-MiniLM-L6-v2")
texts = [chunk["text"] for chunk in chunks]
embeddings = model.encode(texts, convert_to_numpy=True)
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
print("Vector index created with", index.ntotal, "chunks")
Now create a Vector RAG retrieval function.
def vector_rag_search(query, top_k=3):
query_embedding = model.encode([query], convert_to_numpy=True)
distances, indices = index.search(query_embedding, top_k)
results = []
for idx in indices[0]:
results.append(chunks[idx])
return results
# Test the Vector RAG pipeline
query = "Why are logistics costs rising in the North region?"
vector_results = vector_rag_search(query)
for result in vector_results:
print(result["chunk_id"], ":", result["text"])
The Vector RAG retrieval function encodes the query, performs a nearest-neighbor search against the stored chunk embeddings, and returns the top matching passages. This approach efficiently surfaces the most semantically similar text but does not capture how entities relate across documents.
When to Use Vector RAG, GraphRAG, or Hybrid RAG
Choose Vector RAG when:
- Questions are narrow and factual
- Answers are likely contained within one or two passages
- Speed and simplicity are priorities
- The corpus updates frequently and low-latency indexing is required
Choose GraphRAG when:
- Questions require multi-hop reasoning across entities
- The corpus contains richly interconnected information
- Explainability and traceable reasoning paths matter
- You need corpus-wide synthesis or thematic summaries
Choose a Hybrid approach when:
- Queries vary between local and global in scope
- You want the speed of vector search combined with the reasoning depth of graph traversal
- The application demands both textual evidence and structured grounding
Performance, Cost, and Maintenance Trade-offs
Vector RAG has a lower upfront cost. Indexing is fast, embeddings are straightforward to generate, and updating the index when documents change is simple. Query latency is low because similarity search over embeddings is computationally inexpensive.
GraphRAG carries higher indexing costs. Building the graph requires entity extraction, relationship detection, community detection, and summarization — all of which involve multiple LLM calls over the full corpus. This makes initial setup slower and more expensive. Query time can also be higher depending on graph traversal depth.
Maintenance is easier for Vector RAG. Adding new documents means encoding new chunks and inserting them into the index. With GraphRAG, new documents may require updating entity nodes, re-running community detection, and regenerating summaries to keep the graph consistent.
For production systems, the right choice depends on query complexity, acceptable latency, and budget. Many teams start with Vector RAG and add graph-based retrieval incrementally as their use cases demand richer reasoning.
Limitations and Failure Modes
Vector RAG can fail when:
- The answer requires combining information spread across many chunks
- Semantically similar but irrelevant chunks crowd out the correct context
- Rare entities or niche terminology is poorly represented in the embedding space
GraphRAG can fail when:
- Entity extraction is noisy or inconsistent, leading to a poorly structured graph
- The corpus is too small to benefit from community detection
- Relationship types are ambiguous or domain-specific and hard to extract reliably
- Index construction costs are prohibitive for rapidly changing corpora
Both approaches inherit LLM limitations. Retrieval quality is only as good as the grounding context provided, and neither method eliminates hallucination entirely.
Conclusion
Vector RAG and GraphRAG are complementary rather than competing approaches. Vector RAG excels at fast, similarity-based retrieval for focused questions, while GraphRAG adds structured reasoning across interconnected information for complex, multi-hop queries. Understanding the strengths and failure modes of each method allows practitioners to select the right retrieval strategy — or combine both — to build more reliable and capable RAG systems.
Frequently Asked Questions
Q: Can I use GraphRAG without an LLM for entity extraction? You can use traditional NLP tools such as spaCy or custom named entity recognition models for extraction, but LLM-based extraction generally produces higher-quality entities and relationships.
Q: Is GraphRAG always more accurate than Vector RAG? Not necessarily. For simple, direct questions, Vector RAG is often faster and equally accurate. GraphRAG’s advantage is specific to multi-hop and relational queries.
Q: What graph databases work well with GraphRAG? Neo4j, Amazon Neptune, and NetworkX (for smaller in-memory graphs) are common choices. The right option depends on corpus size and query volume.
Q: How do I decide on chunk size for Vector RAG? Chunk size depends on the nature of your documents and queries. Smaller chunks improve precision for narrow questions, while larger chunks preserve more context for broader questions. Experimentation with your specific corpus is recommended.