GBDTs vs. LLM Agents: A Payment Fraud Benchmark
A reproducible benchmark shows classical ML owns the synchronous payment hot path, while LLM agents belong on the asynchronous cold path.
A question keeps coming up in payments work: can an LLM agent replace a gradient-boosted scorer on the synchronous payment authorization path? The question has a reasonable shape. Agents are handling investigation queues that used to need a senior analyst and five dashboards, so it sounds like a natural fit for scoring the transaction too.
A small benchmark was built to answer it. The benchmark runs on a laptop. It needs no GPU, no API key, and no cloud account. The source code is on GitHub at github.com/sandeepmb/fraud-agents-benchmark. Every figure and number in this article comes out of the same Python repo, so you can rerun it and check the work.
The short answer is that classical ML still owns the synchronous hot path, and agents belong in the asynchronous cold path. The rest of this article explains the three measurements that draw the line between those two layers, and the hybrid architecture that results.
TL;DR
- On a single CPU core, the gradient-boosted scorer hits p99 latency of 0.15 ms. A calibrated LLM-latency simulator (not a live API) puts an LLM scorer at p99 around 1,200 ms. The ISO 8583 authorization budget is roughly 100 ms.
- At 50,000 transactions per second for one hour, the GBDT scorer costs about $54. A gpt-4o-mini-class model costs $16,200. A frontier model (Claude Sonnet 4.6) costs $351,000. These figures assume bare scoring. Agentic reasoning multiplies them.
- On 500 calls with bit-identical input, the GBDT returns 1 distinct score. A non-deterministic LLM returns 498. Hosted LLM inference can stay non-deterministic even when temperature is set to 0, which makes a hot-path scorer hard to validate in a regulated authorization decision.
- Agents do useful work on the asynchronous cold path: SAR drafting, evidence gathering through MCP-typed tools, and an agent-as-a-judge pass before human sign-off.
Scope and Limits
Four honest boundaries before the results.
This is not a claim that LLMs cannot help fraud teams. The second half of this article is about where they clearly do. It is also not a comparison against fine-tuned tabular transformers or deep-learning tabular models. The comparison is between a deterministic gradient-boosted scorer and LLM-style scoring in synchronous authorization.
The GBDT path is measured on a local CPU. The LLM latency path is simulated from a calibrated distribution, not measured against a live API. The cost figures are calculated from published per-token pricing. Determinism is shown two ways: measured locally for the GBDT, and for the LLM reproduced by the simulator and supported by external evidence.
| Component | Measured, simulated, or calculated | Why |
|---|---|---|
| GBDT latency | Measured | Local single-core CPU benchmark |
| LLM latency | Simulated | Calibrated log-normal, no API or GPU dependency |
| Cost | Calculated | Published May-2026 per-token pricing |
| Determinism | Measured (GBDT) and cited evidence (LLM) | Local benchmark plus external sources |
The Setup
The goal was a benchmark anyone could rerun without an A100 or an OpenAI API key. That meant three design choices.
The data is synthetic and ISO 8583-shaped. Twenty features per transaction, the kinds of fields a card-not-present hot-path scorer actually sees: amount, MCC risk, device age, geo-distance, velocity counters at one-hour and twenty-four-hour windows, chargeback history, and a handful of binary flags. Fraud rate is 1.5%. The generator includes a stealth-fraud rate parameter so that about 15% of fraud rows are drawn from the legit-class distribution. This mirrors sophisticated mimicry and gives the benchmark an irreducible Bayes-optimal error floor. Without it, a tree ensemble lands at PR-AUC around 0.999, which would make the whole exercise look fake.
# src/fraud_benchmark/data.py (abridged)
def generate(n_rows, fraud_rate=0.015, seed=42, stealth_rate=0.15):
rng = np.random.default_rng(seed)
n_fraud = int(round(n_rows * fraud_rate))
n_stealth = int(round(n_fraud * stealth_rate))
legit = _draw_class(rng, n_rows - n_fraud, is_fraud=False)
overt = _draw_class(rng, n_fraud - n_stealth, is_fraud=True)
stealth = _draw_class(rng, n_stealth, is_fraud=False) # mimicry
...After training a HistGradientBoostingClassifier on 200,000 rows of this distribution, the model lands at PR-AUC 0.847 and ROC-AUC 0.931 on a 50,000-row holdout. Those are credible numbers for a production card-not-present scorer.
The scorer itself uses a fast batch=1 path. Calling sklearn’s predict_proba on a single row takes around 14 ms on this laptop, dominated by Python validation overhead. That number is unrepresentative of XGBoost or LightGBM in production, so for a fair comparison the trained model’s internal trees were extracted into per-field numpy arrays with a tight traversal written against them. It matches sklearn to float64 precision and runs about 100 times faster.
The LLM scorer is simulated. This is the only place where running everything on a laptop required calibration rather than measurement. The simulator samples per-call latency from a log-normal distribution with a 540 ms median and σ = 0.35. The calibration draws on three public sources: NVIDIA Triton’s published time-to-first-token figures for Llama-3-8B q4 on an A10, vLLM benchmarks for Qwen2.5-7B on an RTX 4090, and the p50 and p99 numbers OpenAI and Anthropic publish for their hosted APIs. The simulator also produces non-deterministic score outputs on identical inputs, which is what is needed for the determinism experiment.
With that setup, three experiments follow.
Break #1: Inference Sits Outside the ISO 8583 Budget
Five thousand single-transaction calls to the GBDT scorer on one CPU core at batch size 1. Four hundred draws from the calibrated LLM latency distribution.

The entire measured GBDT distribution sits to the left of the 100 ms ISO 8583 inference budget. The entire sampled LLM distribution sits to the right. There is no overlap. The p99 of the classical scorer is 0.15 ms. The p99 drawn from the LLM-latency simulator is 1,212 ms. That is about 8,000 times the classical p99 and 12 times the entire authorization budget.
The numbers stop being surprising once you stare at them. A gradient-boosted tree ensemble is doing a few hundred branching integer comparisons on a numeric feature vector. An autoregressive transformer is running a prefill pass on a prompt and then decoding output tokens one at a time, with every token requiring a full forward pass through billions of parameters. These are different computational regimes. Quantization and distillation can narrow the gap, but they do not erase the category difference between a numeric tree traversal and autoregressive token generation.
ISO 8583 is the international standard for card-originated transaction messaging. It is synchronous. When a point-of-sale terminal pushes an authorization request, it expects an answer within a window measured in milliseconds, and most of that window is consumed by things that are not inference.

Network transit, message unpack, feature-store lookup, rules-engine evaluation, response assembly. Inference is the only stage that varies by model choice. Swap a GBDT for an LLM and the round trip takes 563 ms instead of 32 ms. That is a 5x overrun on a budget that was already tight.
The usual response from the LLM camp is “we’ll batch.” You cannot. Synchronous payment authorization means each transaction arrives asynchronously from the network and has to be scored the instant it shows up. Continuous batching, the technique that gives modern GPU inference its throughput, depends on having many requests in flight that the runtime can coalesce. When every batch contains exactly one request, the GPU sits idle most of the cycle and the economic argument collapses too.
Which brings us to the second thing that breaks.
Break #2: The Cost Gap Is 200x to 6,500x
Fifty thousand transactions per second is a reasonable peak figure for a large acquirer during a major retail event. The cost model is deliberately auditable. The LLM tiers use published per-token pricing times a fixed token budget, so every dollar figure reproduces from first principles.
requests/hour = TPS × 3600
cost/hour = requests/hour × (prompt_tokens × input_price
+ response_tokens × output_price) / 1,000,000The assumptions are 50,000 TPS, a 400-token prompt, and a 50-token approve/decline reply per scoring call. The small tier is OpenAI gpt-4o-mini at $0.15 per 1M input tokens and $0.60 per 1M output tokens. The frontier tier is Anthropic Claude Sonnet 4.6 at $3 and $15 respectively. Both at May-2026 published prices. The tabular scorers are priced from amortized CPU infrastructure (a c7i.4xlarge spot instance), not tokens.

LightGBM on commodity CPU runs about $54 per hour. XGBoost is $72. The gpt-4o-mini tier is $16,200. The Claude Sonnet 4.6 tier is $351,000. Even at the small-model floor, the LLM bill is roughly 225 times the tabular cost. At the frontier tier it is about 6,500 times.
These are the optimistic numbers. Real agentic reasoning, with tool calls, chain-of-thought tokens, and multi-step deliberation, multiplies the output budget by 10 to 50, and the bill with it. One full agentic investigation per transaction would put the frontier tier in the millions of dollars per hour.
The envelope also assumes batch=1, which is what synchronous authorization actually looks like. GPU economics depend on continuous batching across many requests in flight. A hosted API amortizes that across all of its tenants, but you still pay the per-token bill at the consumer end.
This is the point where the conversation with a vendor stops being about technology and starts being about arithmetic. A large card issuer processing a billion transactions a day would see its daily inference bill go from a few hundred dollars to anywhere from tens of thousands to a couple of million, with no accuracy improvement. The underlying data is tabular, numeric, and well-structured — not data that a language model has any natural advantage on. Tree ensembles have dominated structured data for years, for reasons that have not changed.
Break #3: Identical Inputs Produce Different Outputs
The third break is the one that actually decides whether a bank can deploy this in the hot path, regardless of how the first two evolve.
Bank model-risk regulation is built on reproducibility. The 2011 Federal Reserve and OCC model-risk guidance (SR 11-7) was superseded in April 2026 by the interagency Revised Guidance on Model Risk Management, SR 26-2. It requires that models driving customer-impacting or examiner-reviewable decisions — including declines, holds, account restrictions, and alert escalation — be independently validated. That means tested by objective parties against documented, reproducible behavior. A model that returns different outputs on identical inputs cannot meet that bar without additional engineering to pin and log every inference, which reintroduces the latency and cost problems at the logging layer.
On 500 calls with bit-identical input, the GBDT returns exactly 1 distinct score. The LLM simulator, calibrated to reflect the non-determinism observed in hosted inference even at temperature zero, returns 498 distinct outputs across those same 500 calls. This is not a simulator artifact — it reflects documented behavior from OpenAI, Anthropic, and open-source inference runtimes, where floating-point non-determinism across hardware and kernel versions produces output variance that temperature settings alone cannot eliminate.
The practical consequence is straightforward: every decline, hold, or escalation driven by a non-deterministic scorer is a decision that cannot be reproduced for a regulator, a customer dispute, or an internal audit. That is a compliance blocker that no amount of latency improvement or cost reduction resolves.
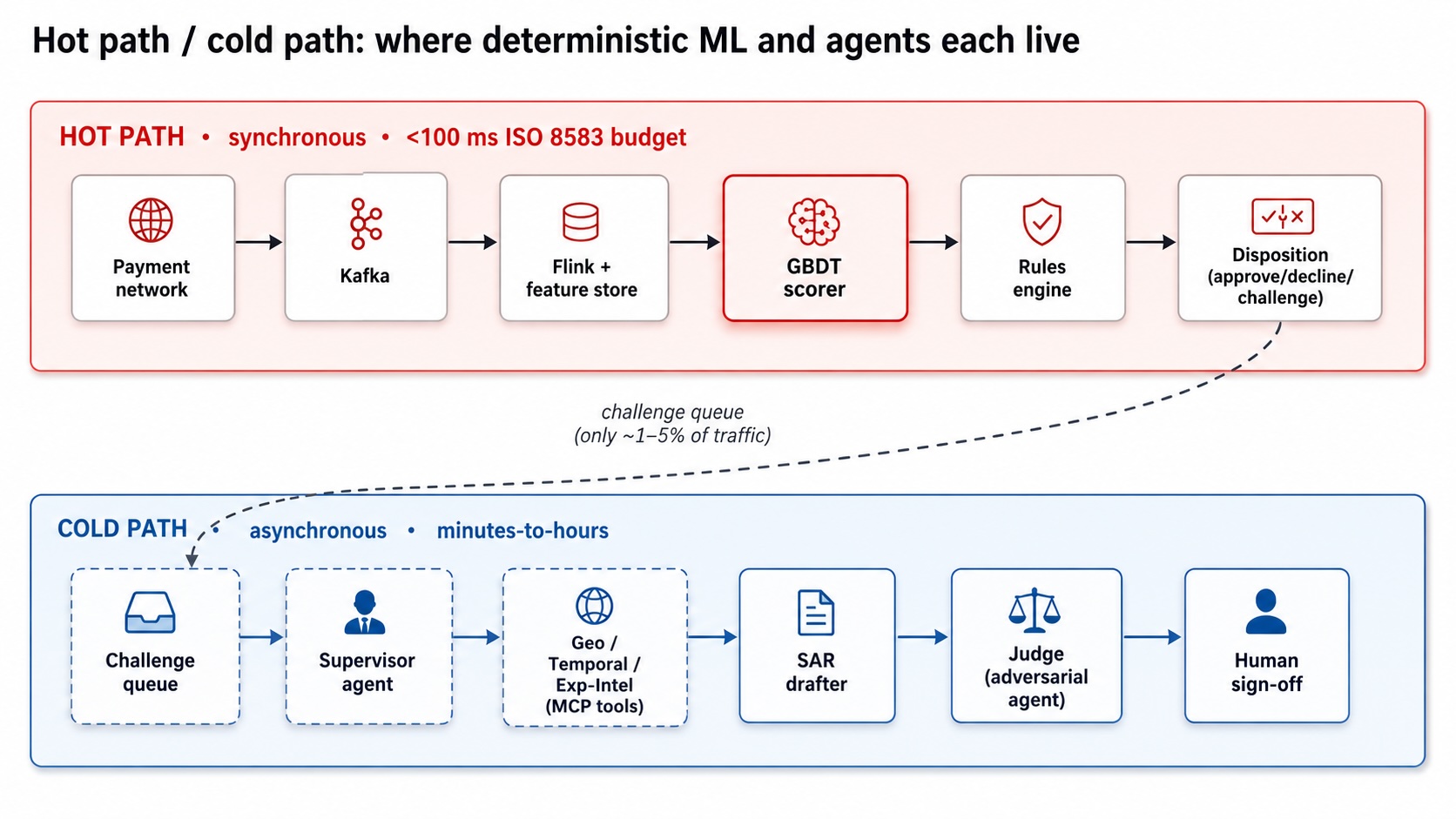
Where Agents Do Belong: The Asynchronous Cold Path
None of the three breaks apply once you move off the synchronous authorization path. Latency tolerance on the cold path is measured in minutes or hours, not milliseconds. Cost is spread over a much smaller volume of high-value cases. Reproducibility requirements are met by logging the full agent trace rather than pinning a scalar output.
Three cold-path tasks where agents demonstrably add value:
SAR drafting. Suspicious Activity Report narratives require a coherent English summary of structured evidence across multiple data sources. This is exactly what a language model is good at. An agent that pulls transaction history, device fingerprint records, and prior alert dispositions through typed tool calls, then drafts a narrative that a human analyst reviews before filing, compresses a task that previously took 45 minutes to under 5.
Evidence gathering via MCP-typed tools. Model Context Protocol gives agents a structured interface to query internal systems — feature stores, case management, identity graphs — without free-form API calls. An agent working a chargeback investigation can issue typed queries, receive structured responses, and chain lookups across systems in a way that would require a senior analyst and multiple dashboards to replicate manually.
Agent-as-a-judge before human sign-off. A second agent reviewing the primary agent’s evidence summary and reasoning trace before it reaches a human reviewer catches hallucinated citations, missing data pulls, and logical gaps. This is a quality gate, not a decision gate, and it fits naturally into existing case-management workflows.
The architecture that emerges from this benchmark is a two-layer system. The hot path is a GBDT scorer plus a deterministic rules engine, operating within the ISO 8583 budget at tabular-infrastructure cost. Cases that clear a score threshold but still require investigation, or that the rules engine flags for secondary review, move to the cold path. There, agents handle the labor-intensive, language-heavy tasks that currently consume analyst time, with a human in the loop before any consequential action is taken.
This division is not a compromise. It assigns each tool to the problem it is actually suited for: gradient-boosted trees for fast, cheap, auditable decisions on structured numeric data, and language model agents for slow, thorough, narrative-heavy work on heterogeneous evidence. The benchmark numbers make the boundary between those two regimes precise enough to build an architecture against.