Choosing the Right Agentic Design Pattern: A Decision Tree Approach
A five-question decision tree to help you select the right agentic design pattern based on task properties, constraints, and trade-offs.
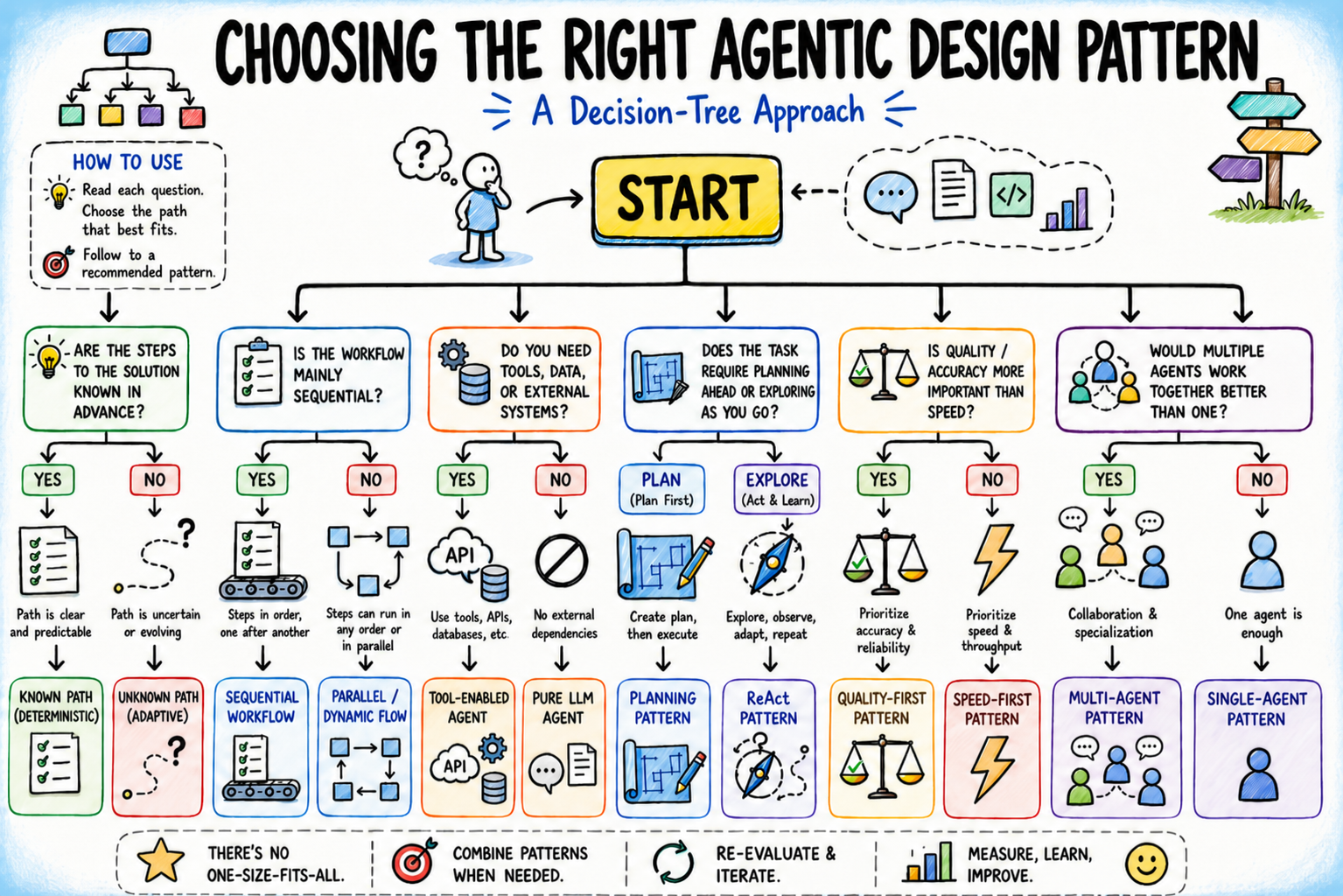
In this article, you will learn how to apply a structured decision tree to choose the right agentic design pattern for any AI system you are building.
Topics we will cover include:
- Why pattern selection is a critical design decision, and what assumptions underlie each major agentic design pattern.
- A five-question decision tree that maps concrete task properties to the most appropriate starting pattern.
- Common failure signals for each pattern and the targeted fixes that address them.
Introduction
Most agentic architecture mistakes start with a simple misread of the problem. Developers often pick a pattern based on what looks impressive or familiar, not what the task actually needs. A multi-agent system from a talk can look like the “right” answer, so they spend weeks building orchestration for something a single well-prompted agent with a couple of tools could handle in a day. Or they go the other direction, keep things too simple, and only discover in production that the system can’t adapt or scale, forcing a redesign under pressure.
Pattern selection is where the real design work happens. The agentic design patterns themselves are well documented. What is less documented is the decision logic for choosing between them. That logic is what this article is about.
The approach here is a decision tree: a series of questions about your task, your constraints, and your acceptable trade-offs that leads you to the right starting pattern. The tree doesn’t produce a final answer; agent architectures evolve as feedback accumulates. But it gives you a principled starting point, and it makes the reasoning behind your choice clear enough to revisit when things change.
Why Is Agentic Design Pattern Selection Important?
Before working through the decision tree, it is important to clearly define what is at stake when selecting a design pattern.
Each agentic design pattern is based on specific assumptions about the structure and demands of a task. Here are some of them:
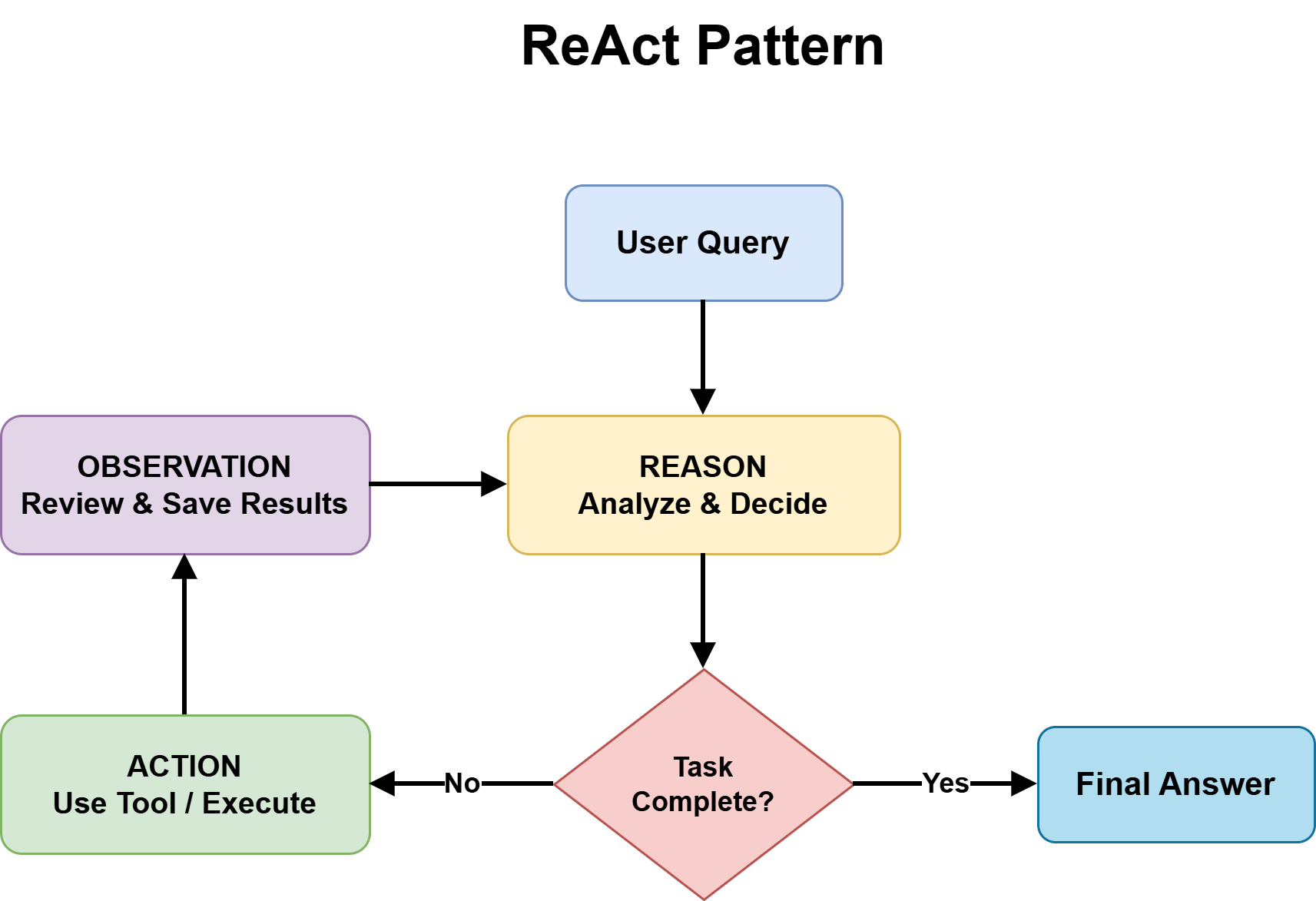
- ReAct pattern treats the next best action as not fully knowable in advance, and relies on combining reasoning with tool use at each step to improve decisions.
- Planning is based on the idea that the major structure of the task can be identified upfront, and that defining an execution roadmap improves downstream reliability.
- Reflection pattern is grounded in the expectation that first-pass outputs are often incomplete or flawed, and that iterative self-critique and refinement improve final quality enough to justify the added cost.
- Multi-agent approaches operate on the belief that the task benefits from decomposition into specialized roles, where parallel or modular execution outweighs the overhead of coordination.
When these assumptions match the task, the pattern adds real value. When they don’t, it adds overhead without improving results. For instance, planning can become rigid when task structure only emerges during execution, reflection can waste resources on simple queries, and multi-agent setups can add unnecessary complexity for problems a single agent can solve.
The decision tree below helps guide deliberate pattern selection. Each branch reflects a key task property that determines which assumptions actually hold.
A Decision Tree for Choosing the Right Agentic Design Pattern
The tree has five branching questions, each one narrowing the pattern space based on a concrete property of the task at hand. Work through them in order.
Question 1: Is the Solution Path Known in Advance?
This question separates fixed workflows from adaptive ones.
A known solution path means the full step-by-step process can be defined before execution. For example:
- Invoice processing: extract fields → validate → store → confirm
- Employee onboarding: create accounts → send welcome email → assign manager → schedule orientation
These are predictable workflows where the same steps apply every time.
An unknown solution path means each step depends on previous outputs. Research tasks that follow new evidence, customer support that branches based on user input, or debugging that shifts hypotheses based on earlier results cannot be fully planned in advance.
If the path is known → go to Question 2a. If unknown → go to Question 2b.
Question 2a: Is This a Fixed Workflow?
For known, stable paths, use a sequential workflow pattern. The agent follows explicit steps in order, passing outputs from one stage to the next until completion.
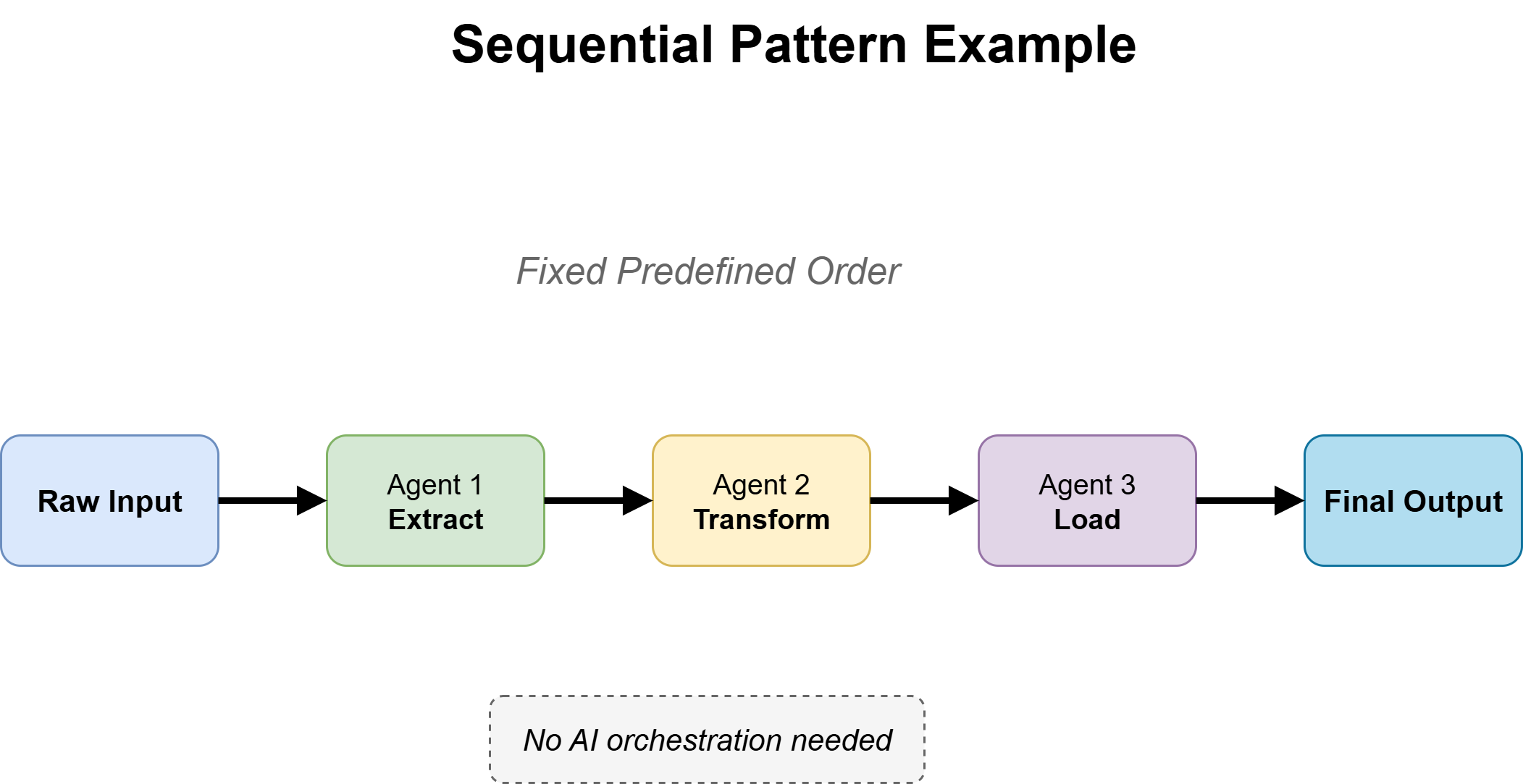
The key design choice is where reasoning is needed. Use the model only for tasks like interpretation or generation, while deterministic code handles everything else. This keeps systems fast, predictable, and cost-efficient.
The main failure mode is over-engineering — adding ReAct-style reasoning where every step is already defined. If the process is fully deterministic, the agent should execute, not decide.
If the workflow starts breaking on edge cases or requires new steps not originally defined, it may be time to move to Question 2b.
Question 2b: Does the Task Require Tool Access or External Information?
For tasks with unknown solution paths, the next question is whether the agent needs to interact with the external world — query databases, call APIs, retrieve documents, run code — or whether it can operate purely on information already in its context.
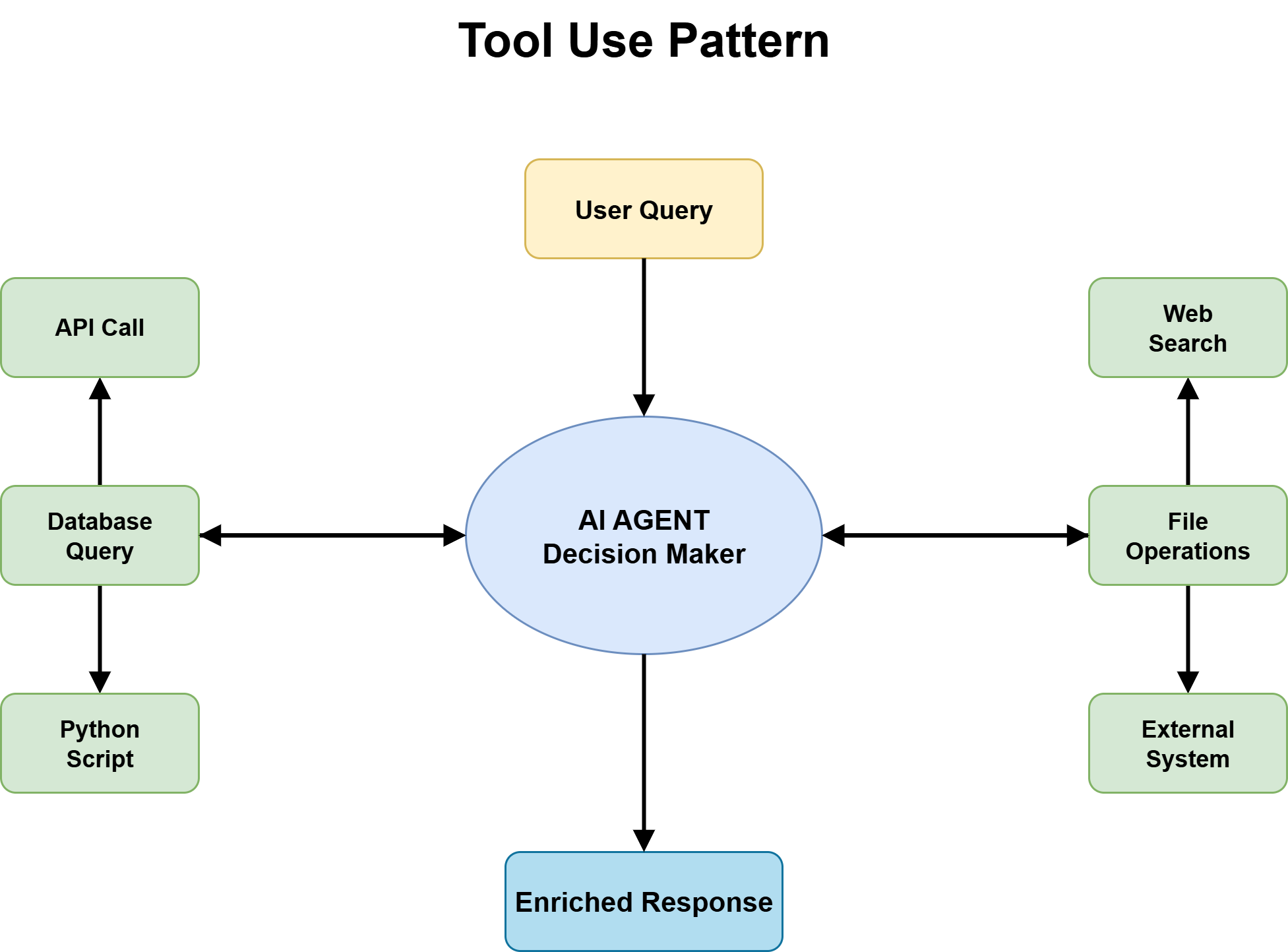
The answer is almost always yes: tool use is required. An agent that can only reason over its training data and the conversation context handles a narrow slice of real-world tasks. The moment the task involves current information, external state, or system-level actions, tool use becomes the foundation everything else sits on.
Effective tool design with clear contracts, inputs, and outputs matters, but for pattern selection the main point is simpler: tools add capability without changing the reasoning pattern. A ReAct agent with tools is still ReAct, and a planning agent with tools is still planning. Tool use sits under the reasoning layer, not alongside it.
Move forward to Question 3 with tool use assumed unless the task is genuinely self-contained.
Question 3: Is the Task Structure Articulable Before Execution Begins?
This question separates Planning from ReAct and is often skipped in practice, with developers defaulting to ReAct. ReAct works by iteratively alternating between reasoning steps and tool actions, using the results of each step to decide what to do next until a stopping condition is met.
A task is structurally articulable when it can be broken into ordered subtasks with clear dependencies before execution. The full details may be unknown, but the main stages and sequence are clear. For example, building a feature (design → implement → test), provisioning systems in order, or producing a research report (gather → synthesize → write) all have a defined structure.
The planning pattern works well when this structure exists, because it exposes dependencies early and avoids mid-execution surprises. Without it, agents can only discover mistakes after spending time and compute on the wrong path.
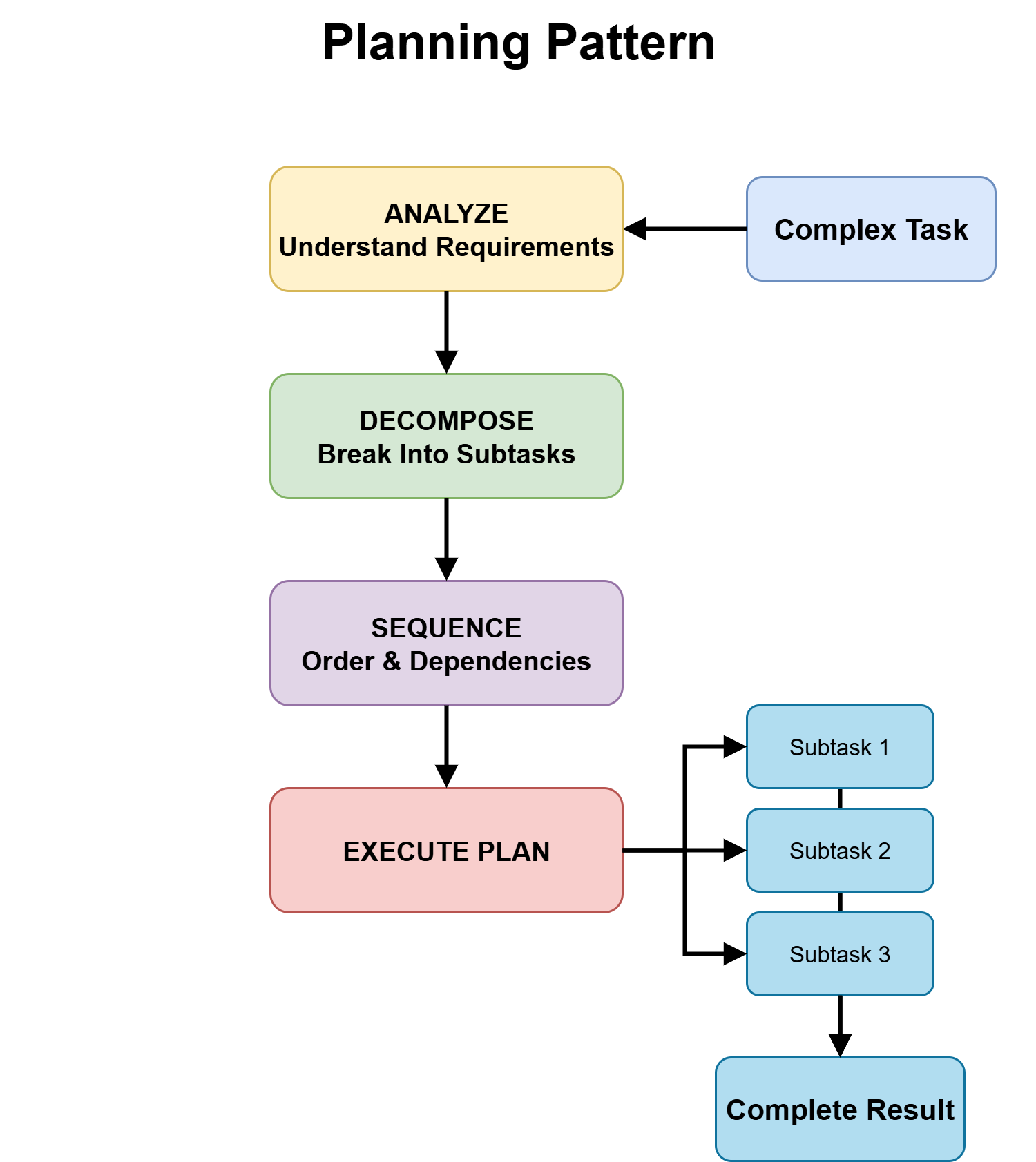
But planning also has costs: an extra upfront step, reliance on the quality of the initial plan, and reduced flexibility when real-world conditions differ from expectations. When structure only becomes clear through interaction and feedback, planning can be misleading.
If the task is structurally clear → use Planning with ReAct inside steps. If structure emerges during execution → use ReAct and move to Question 4.
Question 4: Does Output Quality Matter More Than Response Speed?
This question introduces the reflection pattern — the generate–critique–refine cycle — and determines whether it should be added on top of the chosen pattern.
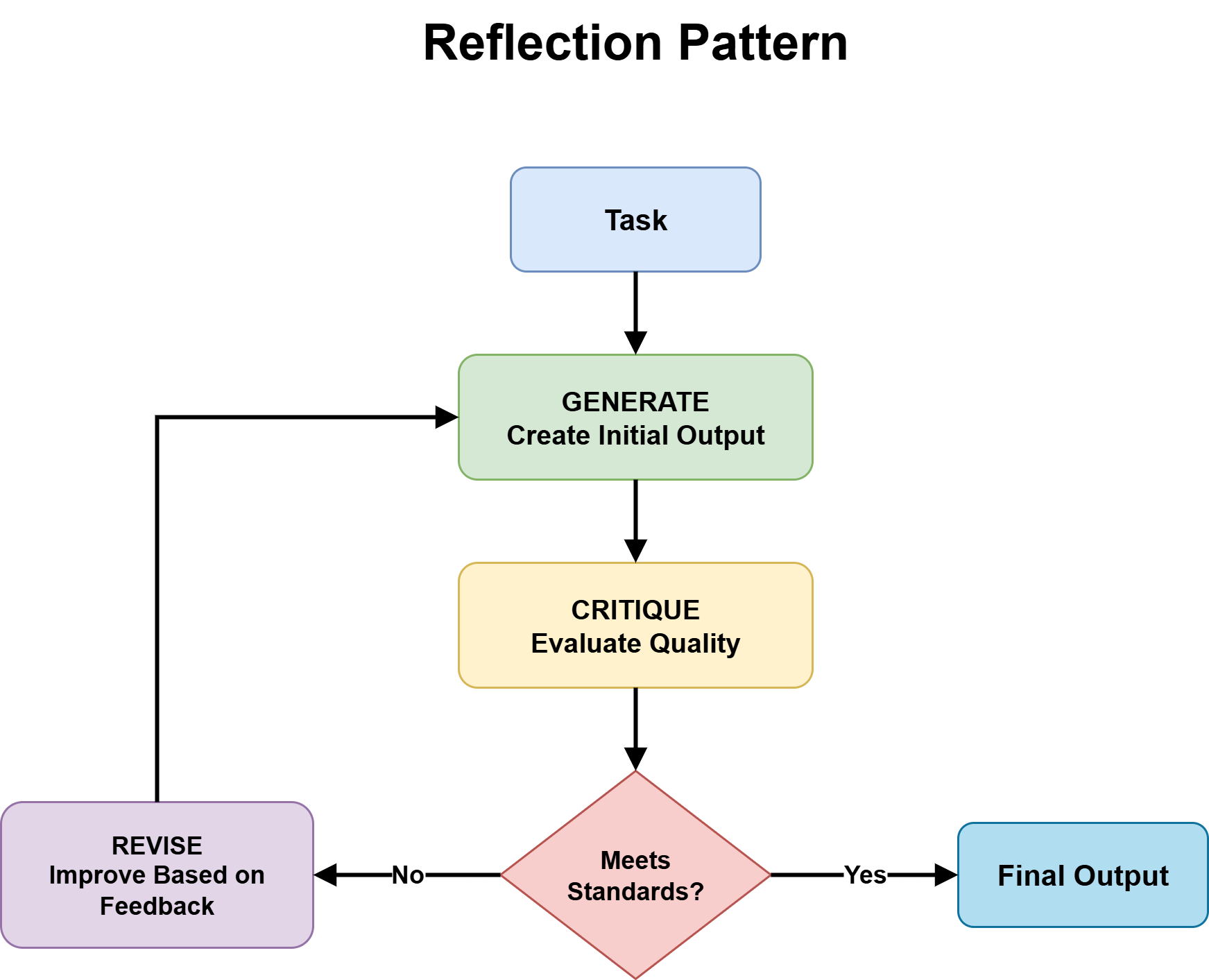
Reflection is useful when two conditions are met:
- First, there are clear quality criteria the output can be checked against — such as a valid SQL query, a well-reasoned argument, or a contract with missing elements.
- Second, the cost of errors is high enough to justify an extra pass, such as deployed code or client-facing content where mistakes carry real consequences.
When both conditions hold, the reflection pattern improves output reliability by catching flaws before they propagate downstream. When neither holds — the task is low-stakes and the criteria are vague — reflection adds latency and cost without a meaningful quality gain. Use it selectively, not by default.
If quality outweighs speed → add Reflection. If speed matters more → skip Reflection and move to Question 5.
Question 5: Can the Task Be Decomposed Into Independent Subtasks?
This is the final branching question, and it determines whether a multi-agent approach is warranted.
Decomposition is meaningful when subtasks can run in parallel or when specialized agents outperform a generalist. For example, a pipeline that simultaneously retrieves data, generates analysis, and drafts a summary benefits from multi-agent execution. So does a system where one agent plans, another executes, and a third validates results.
Multi-agent systems introduce real coordination overhead: shared state management, inter-agent communication, and failure handling across agents. These costs are only justified when the task is complex enough that a single agent would struggle with the full scope, or when parallelism delivers a meaningful speed or quality advantage.
If the task decomposes cleanly → use a multi-agent pattern. If it is better handled as a single continuous thread → stay with a single-agent pattern.
Applying the Decision Tree in Practice
Working through these five questions produces a starting architecture, not a final one. The right pattern for a task at week one may not be the right pattern at week eight, once real usage data reveals where the system actually struggles.
The more important habit is using the tree to make the reasoning behind your choice explicit. When you can articulate why you chose Planning over ReAct, or why you added Reflection, you have something to revisit when the system misfires. Undocumented intuition is harder to improve.
A few practical notes on applying the tree:
- Start simpler than you think you need to. A sequential workflow or single ReAct agent with good tools solves more problems than expected. Complexity should be earned, not assumed.
- Treat failure signals as branching cues. If a sequential workflow keeps breaking on edge cases, that is a signal to move toward ReAct. If a ReAct agent produces inconsistent output quality, that is a signal to add Reflection. The tree is not just for initial selection — it is a map for iteration.
- Separate tool design from pattern selection. Tools are capabilities; patterns are reasoning structures. Improve them independently. A poorly designed tool is a tool problem, not a pattern problem.
Agentic design patterns are not mutually exclusive, and most production systems combine more than one. The decision tree helps you choose the right foundation and add complexity only where task properties justify it.