Building Context-Aware Semantic Search in Python with LLM Embeddings
Learn to build a semantic search engine combining embedding-based similarity with metadata filtering. No API key required.
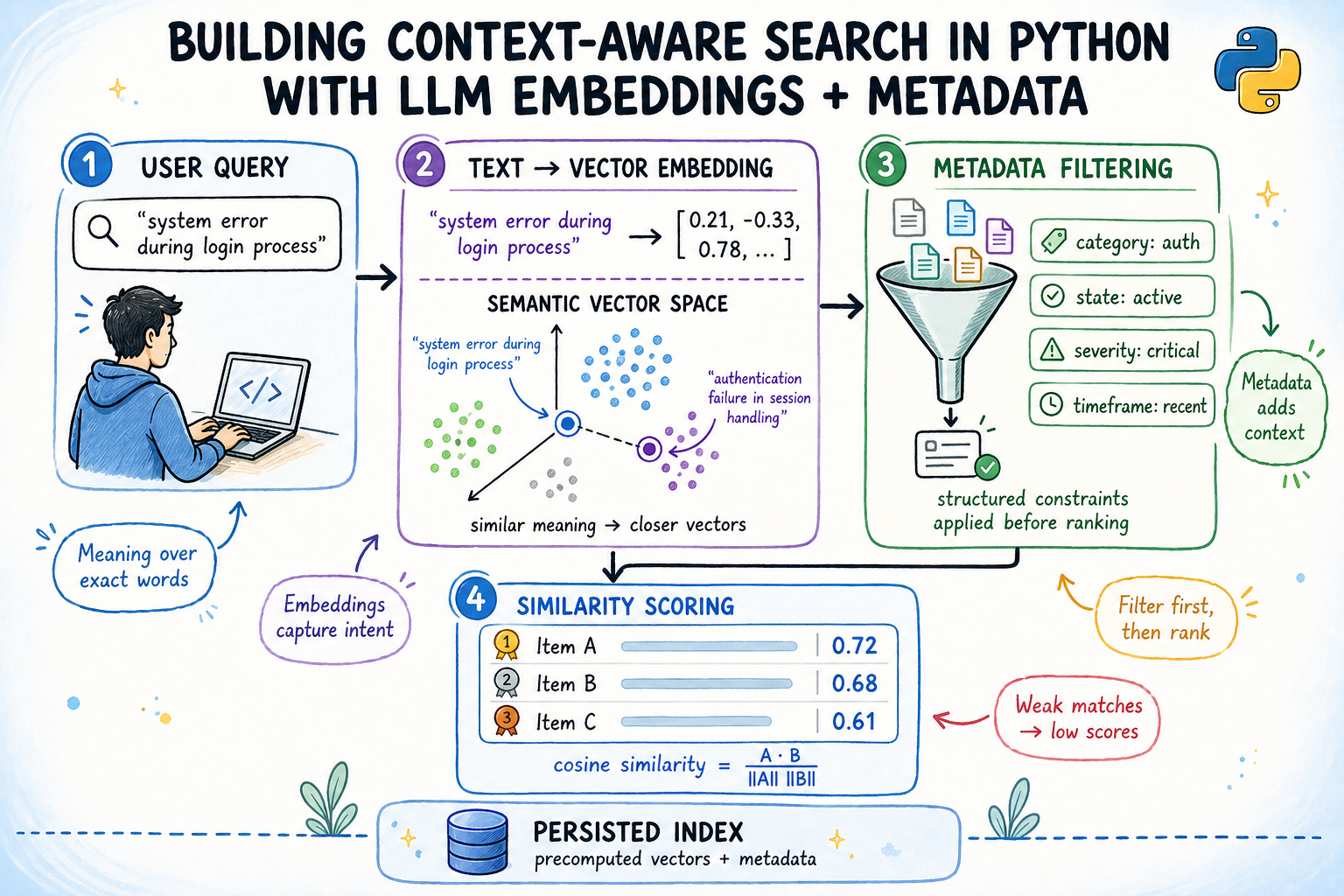
In this article, you will learn how to build a context-aware semantic search engine in Python that combines embedding-based similarity with structured metadata filtering.
Topics we will cover include:
- How sentence embeddings and cosine similarity work together to find semantically relevant documents.
- How to build a metadata-aware search index that filters by team, status, priority, and date before scoring candidates.
- How to persist the index to disk so embeddings are computed only once and reloaded efficiently on subsequent runs.
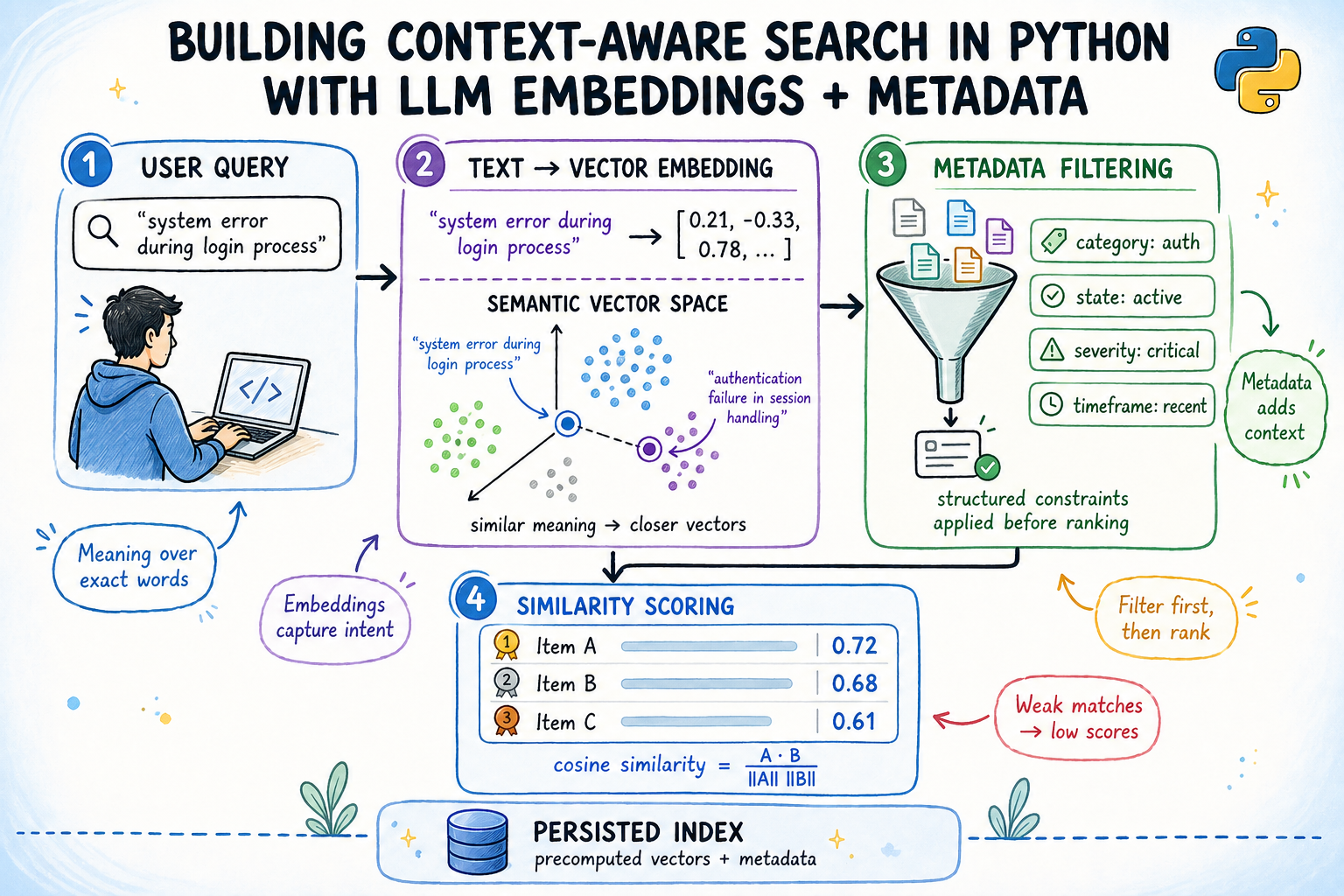
Introduction
Keyword search breaks the moment a user types something a document doesn’t literally say. A support engineer searching for “login keeps failing” won’t find a ticket titled “OAuth2 token refresh race condition”, even though that’s exactly what they need. This is the core problem that context-aware semantic search aims to solve.
Semantic search solves this by converting text into dense vector representations called embeddings, where meaning determines proximity rather than exact word overlap. Layer structured metadata filters on top — by date, status, team, priority — and you get a system that understands what someone is asking while respecting contextual constraints at the same time.
This article walks through building that system end-to-end: embeddings from a local pretrained model, a metadata-aware index, cosine similarity ranking, and an index that persists across restarts without requiring re-encoding.
You can get the code on GitHub.
What You Will Build
A simple context-aware search engine over a corpus of engineering support tickets. By the end you will have:
- 384-dimensional embeddings generated locally from a pretrained model, no API key required
- A search index that filters by team, status, priority, and date before scoring
- Cosine similarity ranking over the filtered candidate pool
- A persisted index that reloads without re-encoding
Prerequisites: Python 3.8+, basic familiarity with NumPy and working with lists of dictionaries.
Install dependencies:
pip install sentence-transformers numpyUnderstanding How Semantic Search Works
A sentence embedding model takes a string and returns a fixed-length vector of floating-point numbers. The model is trained so that sentences with similar meanings produce vectors pointing in similar directions in high-dimensional space.
Cosine similarity measures the angle between two vectors:
$$\text{cosine similarity}(A, B) = \frac{A \cdot B}{|A| , |B|}$$
When vectors are unit-normalized — meaning their length equals 1.0 — this simplifies to the dot product: A · B. Scores range from -1 (opposite) to 1 (identical). In practice, unrelated documents score around 0.1–0.25, and strong matches score above 0.6.
So why does metadata filtering matter? Embedding models encode semantic content. They do not encode who wrote a document, what team owns it, or when it was created. These attributes live outside the text and must be handled separately. Combining both signals — semantic score and metadata constraints — is what makes search useful in real systems.
Setting Up the Dataset
We’ll work with 20 engineering support tickets across three teams — infrastructure, backend, and frontend — with four priority levels, two statuses, and a two-month date window.
Each ticket is a plain dictionary. The text field is what gets embedded; everything else is metadata for filtering.
To keep things concise, a truncated list is shown here instead of the full code block. The complete set of tickets is available in this GitHub gist.
from datetime import date
tickets = [
{"id": "T-101", "team": "infrastructure", "status": "open", "priority": "high",
"created": date(2025, 11, 3),
"text": "Kubernetes pod keeps crashing with OOMKilled — memory limits on the ML inference container are set too low for the model it loads at runtime."},
{"id": "T-102", "team": "infrastructure", "status": "open", "priority": "high",
"created": date(2025, 11, 8),
"text": "Nginx ingress returning 502 after rotating TLS certificate. Chain is valid per openssl verify but the backend handshake fails immediately."},
{"id": "T-103", "team": "infrastructure", "status": "resolved", "priority": "medium",
"created": date(2025, 10, 14),
"text": "Terraform state file locked in S3 — a team member force-applied a plan without releasing the DynamoDB lock first."},
...
{"id": "T-401", "team": "infrastructure", "status": "open", "priority": "medium",
"created": date(2025, 11, 11),
"text": "CI pipeline fails on ARM64 runners — base Docker image has no ARM variant, exec format error at build stage."},
{"id": "T-402", "team": "infrastructure", "status": "resolved", "priority": "high",
"created": date(2025, 10, 9),
"text": "VPN gateway latency spikes at peak hours — BGP route flapping between two peers causing intermittent packet loss across the private subnet."},
]A quick check on the shape of the corpus before moving on:
open_ct = sum(1 for t in tickets if t["status"] == "open")The full dataset and all remaining code are available in the GitHub repository. With the dataset defined, you have everything needed to build the embedding index, apply metadata filters, and run ranked semantic queries against real engineering tickets.