7 Barriers Between Data Teams and Self-Healing Pipelines
Self-healing data pipelines remain out of reach for most teams. Here are the seven key barriers standing in the way.

Introduction
Most AI examples of data engineering revolve around one thing: fixing a pipeline. An engineer opens up Claude Code, pastes some logs, and a pull request is made.
Semantics are fundamental here. Because when people say “self-healing” what they mean is “self-managing”. The key to success in AI is not defined by manual intervention and interaction — but the absence of it.
The dream for data teams is a system whereby data pipelines and workflows generally succeed without any human intervention at all. However, there are barriers that lie in between us and this golden future.
Agents require context — fixing a pipeline may be due to a transient error, upstream schema change, or something uncontrollable entirely like a human dropping a table. Experience provides engineering teams with the know-how of how to fix these; context agents are missing.
A shift in mindset will also be apparent. The old pattern of “New branch, merge, re-run” is distinctly slow and not agent-y. Unless we change our patterns and allow agents to merge PRs as well, a large mindset shift is required.
Finally, data does not “branch” well. Projects like LakeFS promised to make “Git for data” mainstream, but it has not taken hold. Zero-copy cloning has been discussed for years, but it is still not widely used. The distinctions between code and data are not obvious.
In this article, we’ll cover 7 barriers between the typical data stacks of today and the nirvana of self-healing, autonomous data pipelines.
Barrier 1 | Context and Failure Recall
Pipelines can fail for a plethora of reasons, and being able to fix pipelines at all is a baseline requirement for any AI system. We can categorise failures into a few broad types:
- Infrastructure issues
- Code issues
- Data issues
- Transient or third-party issues
Generally, fixing data issues requires knowledge of the system. For example, Acme’s Kubernetes cluster may only be accessible by Bob, who holds a special access key hidden in AWS Secrets Manager with a non-standard header. AI doesn’t know about Bob’s key, so it won’t be able to fix the cluster.
Similarly, Analyst Sophie may know that the right approach at Widgets Incorporated is to account for the fact that sales are reported in multiple currencies, and to adjust the numbers accordingly. AI doesn’t know how to treat those numbers.
AI may also not know that to handle failures from the internal API, you simply need to retry between 2:47am and 3:12am.
These are deliberately simplified examples, but they illustrate the point that the knowledge required to fix different types of errors often exists only inside individuals’ heads. It is not enough to speak about “metadata context.” While gathering lineage, logs, code, documentation, and other written-down context is undoubtedly imperative, the deeper problem is tacit institutional knowledge.
As data practitioners, we’ve all encountered a situation where someone has thought:
“How on earth could I have known that?”
At the end of the day, only humans know where the bodies are buried.

Barrier 2 | Elastic Infrastructure
Considering infrastructure-type issues specifically, “elastic infrastructure” is a useful framing. Elastic infrastructure does not just scale — it also exposes an API to manage it.
A standard EC2 instance would not qualify as elastic, as it does not scale beyond a certain point. A Kubernetes cluster on a locked-down machine would not be elastic with respect to the cloud, as there would be no API through which it could be managed.
The reason this matters is that AI will require access to infrastructure in order to recover from infrastructure failures.
SaaS providers are well-positioned here. SaaS providers necessarily absorb the infrastructure management burden from data teams, for a fee. This is a very AI-friendly approach, though it runs into complications at Barrier 6.
Barrier 3 | Operational Agents and Quality Data
Pete in Finance has overwritten the Supply and Operations Planning Google Sheet for the US again. The international forecasts are broken, and your pipeline is failing. There are 0 rows in us_forecast_dec_v1 and forecasts_agg is stale.
AI is telling you the connectors are fine but there was no data. It can’t do anything.
What is the solution here?
- Option 1: Let AI hallucinate the forecasts
- Option 2: Let AI hallucinate the forecasts in your data warehouse, and re-run the Google Sheet pipeline later
- Option 3: AI tells Pete to upload the forecasts
- Option 4: There is a warm pool of rented humans. When this type of pipeline fails, the AI instructs the warm pool to bother Pete in person until he fixes the pipeline himself
There is no right answer. All options range from bad to ludicrous. Option 4 doesn’t really require AI at all — it requires something called teamwork.
Quality data is, as ever, the most important factor for a data engineer. Data teams should be asking in interviews: “How good is your data?” It is such a determinant of quality of life that it is surprising it does not receive more attention.
That is not to say that operational agents have no place. Genuine fat-finger errors could easily be corrected by an operational agent. For example, if a new deal is entered as $10m but the correct number is $1m, an agent with a Salesforce API key could amend the data and restart the pipeline.
Barrier 4 | Git for Data
The previous example raises an important question: should AI agents edit production?
If you’ve managed multiple Salesforce environments, you know the pain. But that separation exists for a reason. If the account executive genuinely has landed a $10m deal, it would be far better for the agent to edit the staging Salesforce instance rather than the production one.
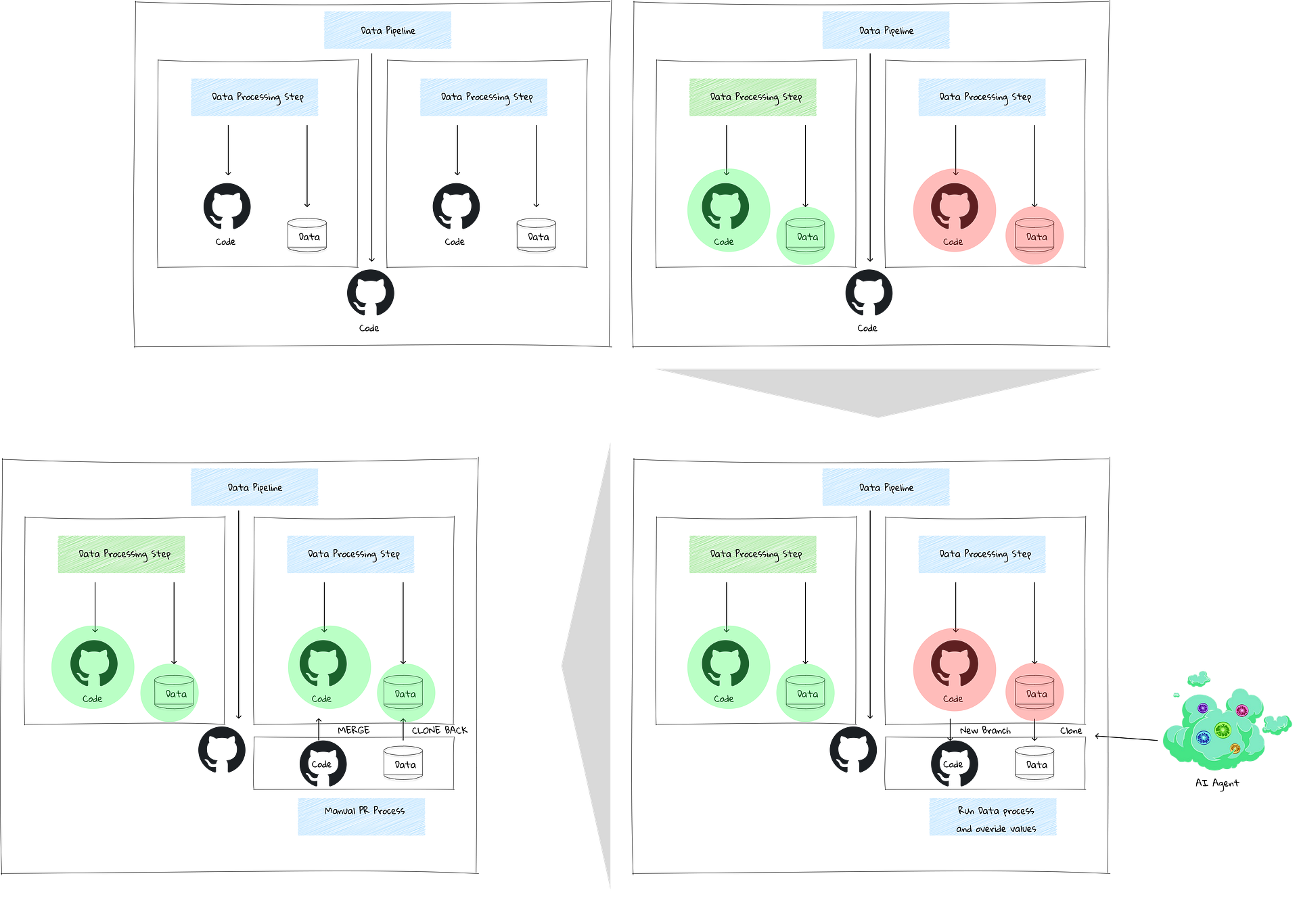
The above is a high-level rendering of what a git-for-data workflow would look like. A simpler version is shown below.
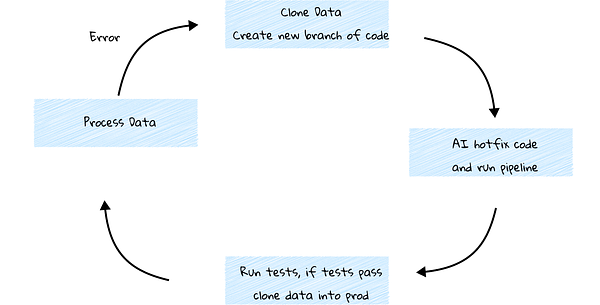
In both cases, AI needs a new branch to do its work. That branch needs zero-copy clones of the data, a git-for-data approach, and the ability to efficiently swap in the corrected data at the end.

Without this structure in place, it is hard to see how AI can be trusted to reliably fix things without creating a governance nightmare in which it holds write access to production data.
Companies like Snowflake are well-positioned here, having supported zero-copy cloning for some time. Motherduck also supports this feature. The clearest winner, however, is Apache Iceberg.
Iceberg supports time travel, rollback, and git-for-data workflows. Companies like Bauplan have built compute engines around Iceberg, creating an AI-friendly development experience. AI adoption should be a significant catalyst for Iceberg’s growth.
Barrier 5 | Pervasion Through the Industry
Self-healing architecture hits a problem when we talk about interoperability.
Fivetran and dbt made a significant push around open data infrastructure in 2025. This is not the same thing as open-source data infrastructure — rather, it refers to a modular data architecture approach, whereby different functions are served by different tools.
There is no point having a self-healing architecture if the underlying components do not support it. Service providers must expose relevant APIs that support self-healing functionality, or the broader pattern cannot work.
For example, suppose there is a silent failure in an ELT provider: the sub-schema changes such that columns and types remain the same, but values change. Perhaps currencies are now reported in Yen as well as USD, but the currency and local_value columns still exist with the same names.
The correct remediation might be to amend the ELT job in its staging environment, verify the rest of the pipeline against that staging data, promote the corrected data, and then switch over the erroneously succeeding ELT job. Many ELT tools simply do not provide the APIs required to support this workflow. If you controlled the pipeline as a Python script, there would be no problem — but that flexibility is rarely available with managed connectors.
This creates significant pressure on today’s ETL vendors to open up their platforms or risk being bypassed entirely. It is one of the largest barriers between the modular systems of today and truly autonomous, self-healing architecture. The alternative is for each individual component in the stack to become independently self-healing — the theory being that if every part heals itself, the whole system follows.
Barrier 6 | Agent Sandbox
For AI agents to act safely on data infrastructure, they need an isolated environment in which to operate — a sandbox. Without a contained space where agents can test fixes, run validations, and verify outcomes before touching production systems, the risk of cascading failures or silent data corruption is too high to accept.
The sandbox must be a full-fidelity replica of the production environment: same schemas, same data volumes, same downstream dependencies. Anything less and the agent’s test results may not reflect what will actually happen in production. This is closely related to the git-for-data problem in Barrier 4, but extends beyond storage to include compute, orchestration, and access controls.
Current tooling makes this difficult. Spinning up a complete sandbox environment on demand remains expensive and slow for most teams. Until the infrastructure cost of ephemeral, production-equivalent environments drops significantly, agents will either be constrained to low-risk, read-only tasks or will operate with an unacceptable level of risk in production.
Solving the agent sandbox problem is a prerequisite for any serious deployment of autonomous data pipeline repair, and it is an area where the industry still has substantial ground to cover.